Kubeadm 部署
docker + cri-docker
kubeadm
flannal
$ sudo modprobe br_netfilter
$ sudo apt update
$ sudo apt install -y tcpdump net-tools iptables wget nmap telnet man lsof ipvsadm ipset
$ sudo modprobe br_netfilter
$ sudo apt update
$ sudo apt install -y tcpdump net-tools iptables wget nmap telnet man lsof ipvsadm ipset
$ kubeadm init --cri-socket=unix:///run/cri-dockerd.sock --ignore-preflight-errors=mem --pod-network-cidr=10.244.0.0/16
$ kubectl taint nodes --all node-role.kubernetes.io/control-plane-
nginx deployment 单副本,service 为 nodeport
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: docker.1ms.run/nginx:stable
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: web
---
apiVersion: v1
kind: Service
metadata:
name: nginx
namespace: default
labels:
app: nginx
spec:
type: NodePort
ports:
- port: 80
nodePort: 31532
selector:
app: nginx
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-5846888f49-q4f9c 1/1 Running 0 151m 10.244.0.4 orange723 <none> <none>
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 150m
nginx NodePort 10.106.224.38 <none> 80:31532/TCP 146m
直接访问 service 地址 10.106.224.38 和 pod 地址 10.244.0.4,正常返回
$ curl -I 10.106.224.38
HTTP/1.1 200 OK
$ curl -I 10.244.0.4
HTTP/1.1 200 OK
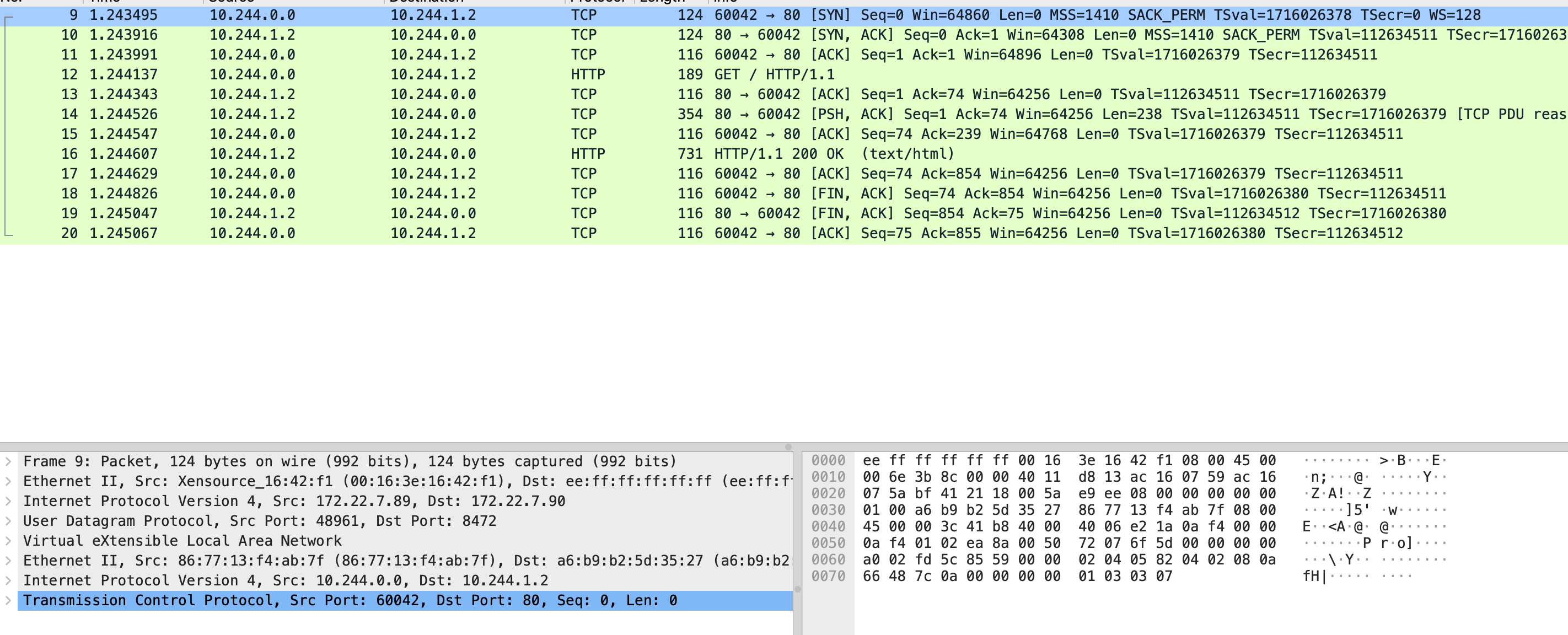
从外部访问测试并分别抓 本机 eth0 cni0 和 pod 的 eth0 网卡
$ tcpdump -i eth0 -s0 -X -nn "tcp port 31532" -w eth0.pcap --print

$ tcpdump -s0 -X -nn -i cni0 -w cni0.pcap --print



$ tcpdump -i eth0 -s0 -X -nn -w nginx.pcap --print

先看 eth0 抓包文件,能看到本地和主机网卡建立连接,三次握手后直接发了 GET / 请求,cni0 抓包中是 10.244.0.1 向 0.4 发送的 GET /,0.1 ip 是 cni0 网卡地址 0.4 是容器的地址,然后 0.4 直接把内容返回给本地 socket 地址也能对应上 37475,最后 nginx 中的抓包则是只和 cni0 网卡通信。
根据抓包内容看出网 iptables:-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES >> -A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUERADE --random-fully 因为不涉及跨主机,后面的 FLANNEL-POSTRTG 正常走一遍流量就返回了
贴下当前机器的 iptables 规则
$ iptables -S -t nat > rules.txt
-----------------------------------------------------------------
-P PREROUTING ACCEPT
-P INPUT ACCEPT
-P OUTPUT ACCEPT
-P POSTROUTING ACCEPT
-N DOCKER
-N FLANNEL-POSTRTG
-N KUBE-EXT-2CMXP7HKUVJN7L6M
-N KUBE-KUBELET-CANARY
-N KUBE-MARK-MASQ
-N KUBE-NODEPORTS
-N KUBE-POSTROUTING
-N KUBE-PROXY-CANARY
-N KUBE-SEP-6E7XQMQ4RAYOWTTM
-N KUBE-SEP-AAOCRVJBUI2XUHEI
-N KUBE-SEP-C3WRBSQHCDQ7BT6J
-N KUBE-SEP-IT2ZTR26TO4XFPTO
-N KUBE-SEP-N4G2XR5TDX7PQE7P
-N KUBE-SEP-YIL6JZP7A3QYXJU2
-N KUBE-SEP-ZP3FB6NMPNCO4VBJ
-N KUBE-SEP-ZXMNUKOKXUTL2MK2
-N KUBE-SERVICES
-N KUBE-SVC-2CMXP7HKUVJN7L6M
-N KUBE-SVC-ERIFXISQEP7F7OF4
-N KUBE-SVC-JD5MR3NA4I4DYORP
-N KUBE-SVC-NPX46M4PTMTKRN6Y
-N KUBE-SVC-TCOU7JCQXEZGVUNU
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
-A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
-A POSTROUTING -m comment --comment "flanneld masq" -j FLANNEL-POSTRTG
-A FLANNEL-POSTRTG -m mark --mark 0x4000/0x4000 -m comment --comment "flanneld masq" -j RETURN
-A FLANNEL-POSTRTG -s 10.244.0.0/24 -d 10.244.0.0/16 -m comment --comment "flanneld masq" -j RETURN
-A FLANNEL-POSTRTG -s 10.244.0.0/16 -d 10.244.0.0/24 -m comment --comment "flanneld masq" -j RETURN
-A FLANNEL-POSTRTG ! -s 10.244.0.0/16 -d 10.244.0.0/24 -m comment --comment "flanneld masq" -j RETURN
-A FLANNEL-POSTRTG -s 10.244.0.0/16 ! -d 224.0.0.0/4 -m comment --comment "flanneld masq" -j MASQUERADE --random-fully
-A FLANNEL-POSTRTG ! -s 10.244.0.0/16 -d 10.244.0.0/16 -m comment --comment "flanneld masq" -j MASQUERADE --random-fully
-A KUBE-EXT-2CMXP7HKUVJN7L6M -m comment --comment "masquerade traffic for default/nginx external destinations" -j KUBE-MARK-MASQ
-A KUBE-EXT-2CMXP7HKUVJN7L6M -j KUBE-SVC-2CMXP7HKUVJN7L6M
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
-A KUBE-NODEPORTS -d 127.0.0.0/8 -p tcp -m comment --comment "default/nginx" -m tcp --dport 31532 -m nfacct --nfacct-name localhost_nps_accepted_pkts -j KUBE-EXT-2CMXP7HKUVJN7L6M
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/nginx" -m tcp --dport 31532 -j KUBE-EXT-2CMXP7HKUVJN7L6M
-A KUBE-POSTROUTING -m mark ! --mark 0x4000/0x4000 -j RETURN
-A KUBE-POSTROUTING -j MARK --set-xmark 0x4000/0x0
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUERADE --random-fully
-A KUBE-SEP-6E7XQMQ4RAYOWTTM -s 10.244.0.3/32 -m comment --comment "kube-system/kube-dns:dns" -j KUBE-MARK-MASQ
-A KUBE-SEP-6E7XQMQ4RAYOWTTM -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.244.0.3:53
-A KUBE-SEP-AAOCRVJBUI2XUHEI -s 10.244.0.4/32 -m comment --comment "default/nginx" -j KUBE-MARK-MASQ
-A KUBE-SEP-AAOCRVJBUI2XUHEI -p tcp -m comment --comment "default/nginx" -m tcp -j DNAT --to-destination 10.244.0.4:80
-A KUBE-SEP-C3WRBSQHCDQ7BT6J -s 172.22.7.89/32 -m comment --comment "default/kubernetes:https" -j KUBE-MARK-MASQ
-A KUBE-SEP-C3WRBSQHCDQ7BT6J -p tcp -m comment --comment "default/kubernetes:https" -m tcp -j DNAT --to-destination 172.22.7.89:6443
-A KUBE-SEP-IT2ZTR26TO4XFPTO -s 10.244.0.2/32 -m comment --comment "kube-system/kube-dns:dns-tcp" -j KUBE-MARK-MASQ
-A KUBE-SEP-IT2ZTR26TO4XFPTO -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp" -m tcp -j DNAT --to-destination 10.244.0.2:53
-A KUBE-SEP-N4G2XR5TDX7PQE7P -s 10.244.0.2/32 -m comment --comment "kube-system/kube-dns:metrics" -j KUBE-MARK-MASQ
-A KUBE-SEP-N4G2XR5TDX7PQE7P -p tcp -m comment --comment "kube-system/kube-dns:metrics" -m tcp -j DNAT --to-destination 10.244.0.2:9153
-A KUBE-SEP-YIL6JZP7A3QYXJU2 -s 10.244.0.2/32 -m comment --comment "kube-system/kube-dns:dns" -j KUBE-MARK-MASQ
-A KUBE-SEP-YIL6JZP7A3QYXJU2 -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.244.0.2:53
-A KUBE-SEP-ZP3FB6NMPNCO4VBJ -s 10.244.0.3/32 -m comment --comment "kube-system/kube-dns:metrics" -j KUBE-MARK-MASQ
-A KUBE-SEP-ZP3FB6NMPNCO4VBJ -p tcp -m comment --comment "kube-system/kube-dns:metrics" -m tcp -j DNAT --to-destination 10.244.0.3:9153
-A KUBE-SEP-ZXMNUKOKXUTL2MK2 -s 10.244.0.3/32 -m comment --comment "kube-system/kube-dns:dns-tcp" -j KUBE-MARK-MASQ
-A KUBE-SEP-ZXMNUKOKXUTL2MK2 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp" -m tcp -j DNAT --to-destination 10.244.0.3:53
-A KUBE-SERVICES -d 10.96.0.1/32 -p tcp -m comment --comment "default/kubernetes:https cluster IP" -m tcp --dport 443 -j KUBE-SVC-NPX46M4PTMTKRN6Y
-A KUBE-SERVICES -d 10.96.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:metrics cluster IP" -m tcp --dport 9153 -j KUBE-SVC-JD5MR3NA4I4DYORP
-A KUBE-SERVICES -d 10.96.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU
-A KUBE-SERVICES -d 10.96.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp cluster IP" -m tcp --dport 53 -j KUBE-SVC-ERIFXISQEP7F7OF4
-A KUBE-SERVICES -d 10.106.224.38/32 -p tcp -m comment --comment "default/nginx cluster IP" -m tcp --dport 80 -j KUBE-SVC-2CMXP7HKUVJN7L6M
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
-A KUBE-SVC-2CMXP7HKUVJN7L6M ! -s 10.244.0.0/16 -d 10.106.224.38/32 -p tcp -m comment --comment "default/nginx cluster IP" -m tcp --dport 80 -j KUBE-MARK-MASQ
-A KUBE-SVC-2CMXP7HKUVJN7L6M -m comment --comment "default/nginx -> 10.244.0.4:80" -j KUBE-SEP-AAOCRVJBUI2XUHEI
-A KUBE-SVC-ERIFXISQEP7F7OF4 ! -s 10.244.0.0/16 -d 10.96.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp cluster IP" -m tcp --dport 53 -j KUBE-MARK-MASQ
-A KUBE-SVC-ERIFXISQEP7F7OF4 -m comment --comment "kube-system/kube-dns:dns-tcp -> 10.244.0.2:53" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-IT2ZTR26TO4XFPTO
-A KUBE-SVC-ERIFXISQEP7F7OF4 -m comment --comment "kube-system/kube-dns:dns-tcp -> 10.244.0.3:53" -j KUBE-SEP-ZXMNUKOKXUTL2MK2
-A KUBE-SVC-JD5MR3NA4I4DYORP ! -s 10.244.0.0/16 -d 10.96.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:metrics cluster IP" -m tcp --dport 9153 -j KUBE-MARK-MASQ
-A KUBE-SVC-JD5MR3NA4I4DYORP -m comment --comment "kube-system/kube-dns:metrics -> 10.244.0.2:9153" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-N4G2XR5TDX7PQE7P
-A KUBE-SVC-JD5MR3NA4I4DYORP -m comment --comment "kube-system/kube-dns:metrics -> 10.244.0.3:9153" -j KUBE-SEP-ZP3FB6NMPNCO4VBJ
-A KUBE-SVC-NPX46M4PTMTKRN6Y ! -s 10.244.0.0/16 -d 10.96.0.1/32 -p tcp -m comment --comment "default/kubernetes:https cluster IP" -m tcp --dport 443 -j KUBE-MARK-MASQ
-A KUBE-SVC-NPX46M4PTMTKRN6Y -m comment --comment "default/kubernetes:https -> 172.22.7.89:6443" -j KUBE-SEP-C3WRBSQHCDQ7BT6J
-A KUBE-SVC-TCOU7JCQXEZGVUNU ! -s 10.244.0.0/16 -d 10.96.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-MARK-MASQ
-A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns -> 10.244.0.2:53" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-YIL6JZP7A3QYXJU2
-A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns -> 10.244.0.3:53" -j KUBE-SEP-6E7XQMQ4RAYOWTTM
看下 31532 端口是否有监听,查看是空的
$ netstat -lnpt|grep 31532
先看 PREROUTING,跳转到 KUBE-SERVICES
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
KUBE-SERVICES 从外部访问目的地址不是 10.106.224.38,只有最后一条匹配
-A KUBE-SERVICES -d 10.96.0.1/32 -p tcp -m comment --comment "default/kubernetes:https cluster IP" -m tcp --dport 443 -j KUBE-SVC-NPX46M4PTMTKRN6Y
-A KUBE-SERVICES -d 10.96.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:metrics cluster IP" -m tcp --dport 9153 -j KUBE-SVC-JD5MR3NA4I4DYORP
-A KUBE-SERVICES -d 10.96.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU
-A KUBE-SERVICES -d 10.96.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp cluster IP" -m tcp --dport 53 -j KUBE-SVC-ERIFXISQEP7F7OF4
-A KUBE-SERVICES -d 10.106.224.38/32 -p tcp -m comment --comment "default/nginx cluster IP" -m tcp --dport 80 -j KUBE-SVC-2CMXP7HKUVJN7L6M
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
KUBE-NODEPORTS,第二条规则能看到设置的 nodeport 端口 31532
-A KUBE-NODEPORTS -d 127.0.0.0/8 -p tcp -m comment --comment "default/nginx" -m tcp --dport 31532 -m nfacct --nfacct-name localhost_nps_accepted_pkts -j KUBE-EXT-2CMXP7HKUVJN7L6M
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/nginx" -m tcp --dport 31532 -j KUBE-EXT-2CMXP7HKUVJN7L6M
KUBE-EXT-2CMXP7HKUVJN7L6M,先看第二条跳转到 KUBE-SVC-2CMXP7HKUVJN7L6M
-A KUBE-EXT-2CMXP7HKUVJN7L6M -m comment --comment "masquerade traffic for default/nginx external destinations" -j KUBE-MARK-MASQ
-A KUBE-EXT-2CMXP7HKUVJN7L6M -j KUBE-SVC-2CMXP7HKUVJN7L6M
KUBE-SVC-2CMXP7HKUVJN7L6M,第一条是源地址不是 10.244.0.0 目的地址是 10.106.224.38 走到 KUBE-MARK-MASQ,看第二条跳转到 KUBE-SEP-AAOCRVJBUI2XUHEI
-A KUBE-SVC-2CMXP7HKUVJN7L6M ! -s 10.244.0.0/16 -d 10.106.224.38/32 -p tcp -m comment --comment "default/nginx cluster IP" -m tcp --dport 80 -j KUBE-MARK-MASQ
-A KUBE-SVC-2CMXP7HKUVJN7L6M -m comment --comment "default/nginx -> 10.244.0.4:80" -j KUBE-SEP-AAOCRVJBUI2XUHEI
KUBE-SEP-AAOCRVJBUI2XUHEI,第一条源地址是 10.244.0.4(容器的地址)跳到 KUBE-MARK-MASQ 去做标记,第二条做了一个 dnat 目的地址是 10.244.0.4:80 就是容器 nginx 的地址
-A KUBE-SEP-AAOCRVJBUI2XUHEI -s 10.244.0.4/32 -m comment --comment "default/nginx" -j KUBE-MARK-MASQ
-A KUBE-SEP-AAOCRVJBUI2XUHEI -p tcp -m comment --comment "default/nginx" -m tcp -j DNAT --to-destination 10.244.0.4:80
这里把 iptables 规则里关于出网的规则整理下。
首先第一条 POSTROUTING 跳转到 KUBE-POSTROUTING,从 pod 到外部网络的包会匹配后两条规则 -A KUBE-POSTROUTING -j MARK --set-xmark 0x4000/0x0 标记,-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUERADE --random-fully 走 snat 变更源地址和随机端口,后面走 FLANNEL-POSTRTG 都没有匹配就正常返回到本机。
-A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
-A POSTROUTING -m comment --comment "flanneld masq" -j FLANNEL-POSTRTG
-A FLANNEL-POSTRTG -m mark --mark 0x4000/0x4000 -m comment --comment "flanneld masq" -j RETURN
-A FLANNEL-POSTRTG -s 10.244.0.0/24 -d 10.244.0.0/16 -m comment --comment "flanneld masq" -j RETURN
-A FLANNEL-POSTRTG -s 10.244.0.0/16 -d 10.244.0.0/24 -m comment --comment "flanneld masq" -j RETURN
-A FLANNEL-POSTRTG ! -s 10.244.0.0/16 -d 10.244.0.0/24 -m comment --comment "flanneld masq" -j RETURN
-A FLANNEL-POSTRTG -s 10.244.0.0/16 ! -d 224.0.0.0/4 -m comment --comment "flanneld masq" -j MASQUERADE --random-fully
-A FLANNEL-POSTRTG ! -s 10.244.0.0/16 -d 10.244.0.0/16 -m comment --comment "flanneld masq" -j MASQUERADE --random-fully
-A KUBE-POSTROUTING -m mark ! --mark 0x4000/0x4000 -j RETURN
-A KUBE-POSTROUTING -j MARK --set-xmark 0x4000/0x0
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUERADE --random-fully
这里关于 --set-xmark 不清晰,也不去管这个到底是做什么的,后面有查到相关资料在补充,直接通过外网访问,看具体哪个 POSTROUTING 规则的包会增加就能知道流量走的那个规则。
在 深入剖析 Kubernetes 中有解释
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE 这条规则设置在 POSTROUTING 检查点,也就是说,它给即将离开这台主机的 IP 包,进行了一次 SNAT 操作,将这个 IP 包的源地址替换成了这台宿主机上的 CNI 网桥地址,或者宿主机本身的 IP 地址(如果 CNI 网桥不存在的话)。当然,这个 SNAT 操作只需要对 Service 转发出来的 IP 包进行(否则普通的 IP 包就被影响了)。而 iptables 做这个判断的依据,就是查看该 IP 包是否有一个“0x4000”的“标志”。你应该还记得,这个标志正是在 IP 包被执行 DNAT 操作之前被打上去的。
$ while true;do curl 101.200.150.26:31532;done
前后对比,能看到 KUBE-POSTROUTING 的 bytes 有变化,FLANNEL-POSTRTG 包很少,pkts 包总数在 1054 分别在 KUBE-MARK-MASQ 和 KUBE-POSTROUTING 两个 chain 里有对应数值。
$ iptables -t nat -L -nvx
-----------------------------------------------------------------
Chain POSTROUTING (policy ACCEPT 132636 packets, 8059995 bytes)
pkts bytes target prot opt in out source destination
127270 7723952 KUBE-POSTROUTING 0 -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes postrouting rules */
0 0 MASQUERADE 0 -- * !docker0 172.17.0.0/16 0.0.0.0/0
120845 7318694 FLANNEL-POSTRTG 0 -- * * 0.0.0.0/0 0.0.0.0/0 /* flanneld masq */
Chain FLANNEL-POSTRTG (1 references)
pkts bytes target prot opt in out source destination
0 0 RETURN 0 -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x4000/0x4000 /* flanneld masq */
11999 720208 RETURN 0 -- * * 10.244.0.0/24 10.244.0.0/16 /* flanneld masq */
0 0 RETURN 0 -- * * 10.244.0.0/16 10.244.0.0/24 /* flanneld masq */
0 0 RETURN 0 -- * * !10.244.0.0/16 10.244.0.0/24 /* flanneld masq */
14 908 MASQUERADE 0 -- * * 10.244.0.0/16 !224.0.0.0/4 /* flanneld masq */ random-fully
0 0 MASQUERADE 0 -- * * !10.244.0.0/16 10.244.0.0/16 /* flanneld masq */ random-fully
Chain KUBE-MARK-MASQ (14 references)
pkts bytes target prot opt in out source destination
1 64 MARK 0 -- * * 0.0.0.0/0 0.0.0.0/0 MARK or 0x4000
Chain KUBE-POSTROUTING (1 references)
pkts bytes target prot opt in out source destination
3513 212636 RETURN 0 -- * * 0.0.0.0/0 0.0.0.0/0 mark match ! 0x4000/0x4000
1 64 MARK 0 -- * * 0.0.0.0/0 0.0.0.0/0 MARK xor 0x4000
1 64 MASQUERADE 0 -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service traffic requiring SNAT */ random-fully
-----------------------------------------------------------------
Chain POSTROUTING (policy ACCEPT 133177 packets, 8092725 bytes)
pkts bytes target prot opt in out source destination
128864 7824074 KUBE-POSTROUTING 0 -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes postrouting rules */
0 0 MASQUERADE 0 -- * !docker0 172.17.0.0/16 0.0.0.0/0
121386 7351424 FLANNEL-POSTRTG 0 -- * * 0.0.0.0/0 0.0.0.0/0 /* flanneld masq */
Chain FLANNEL-POSTRTG (1 references)
pkts bytes target prot opt in out source destination
0 0 RETURN 0 -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x4000/0x4000 /* flanneld masq */
12051 723328 RETURN 0 -- * * 10.244.0.0/24 10.244.0.0/16 /* flanneld masq */
0 0 RETURN 0 -- * * 10.244.0.0/16 10.244.0.0/24 /* flanneld masq */
0 0 RETURN 0 -- * * !10.244.0.0/16 10.244.0.0/24 /* flanneld masq */
14 908 MASQUERADE 0 -- * * 10.244.0.0/16 !224.0.0.0/4 /* flanneld masq */ random-fully
0 0 MASQUERADE 0 -- * * !10.244.0.0/16 10.244.0.0/16 /* flanneld masq */ random-fully
Chain KUBE-MARK-MASQ (14 references)
pkts bytes target prot opt in out source destination
1054 67456 MARK 0 -- * * 0.0.0.0/0 0.0.0.0/0 MARK or 0x4000
Chain KUBE-POSTROUTING (1 references)
pkts bytes target prot opt in out source destination
4054 245366 RETURN 0 -- * * 0.0.0.0/0 0.0.0.0/0 mark match ! 0x4000/0x4000
1054 67456 MARK 0 -- * * 0.0.0.0/0 0.0.0.0/0 MARK xor 0x4000
1054 67456 MASQUERADE 0 -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service traffic requiring SNAT */ random-fully
$ apt install ipvsadm ipset
# 手动加载常用模块
modprobe ip_vs
modprobe ip_vs_rr # 轮询调度算法
modprobe ip_vs_wrr # 加权轮询
modprobe ip_vs_sh # 源哈希
modprobe nf_conntrack_ipv4 # 连接跟踪(若用 IPv4)
直接用 kubeadm 初始化
apiVersion: kubeadm.k8s.io/v1beta4
kind: InitConfiguration
nodeRegistration:
criSocket: unix:///run/cri-dockerd.sock
---
apiVersion: kubeadm.k8s.io/v1beta4
kind: ClusterConfiguration
networking:
serviceSubnet: 10.244.0.0/16
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
$ kubeadm init --config=init.yml --ignore-preflight-errors=mem
$ ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.17.0.1:31532 rr
-> 10.244.0.4:80 Masq 1 0 0
TCP 172.22.7.89:31532 rr
-> 10.244.0.4:80 Masq 1 0 0
TCP 10.244.0.0:31532 rr
-> 10.244.0.4:80 Masq 1 0 0
TCP 10.244.0.1:443 rr
-> 172.22.7.89:6443 Masq 1 3 0
TCP 10.244.0.1:31532 rr
-> 10.244.0.4:80 Masq 1 0 0
TCP 10.244.0.10:53 rr
-> 10.244.0.2:53 Masq 1 0 0
-> 10.244.0.3:53 Masq 1 0 0
TCP 10.244.0.10:9153 rr
-> 10.244.0.2:9153 Masq 1 0 0
-> 10.244.0.3:9153 Masq 1 0 0
TCP 10.244.142.146:80 rr
-> 10.244.0.4:80 Masq 1 0 0
UDP 10.244.0.10:53 rr
-> 10.244.0.2:53 Masq 1 0 0
-> 10.244.0.3:53 Masq 1 0 0
在看下改为 ipvs 后的 iptables 规则有什么变化
$ iptables -S -t nat > ipvsrules.txt
-----------------------------------------------------------------
-P PREROUTING ACCEPT
-P INPUT ACCEPT
-P OUTPUT ACCEPT
-P POSTROUTING ACCEPT
-N FLANNEL-POSTRTG
-N KUBE-KUBELET-CANARY
-N KUBE-LOAD-BALANCER
-N KUBE-MARK-MASQ
-N KUBE-NODE-PORT
-N KUBE-POSTROUTING
-N KUBE-SERVICES
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING
-A POSTROUTING -m comment --comment "flanneld masq" -j FLANNEL-POSTRTG
-A FLANNEL-POSTRTG -m mark --mark 0x4000/0x4000 -m comment --comment "flanneld masq" -j RETURN
-A FLANNEL-POSTRTG -s 10.244.0.0/24 -d 10.244.0.0/16 -m comment --comment "flanneld masq" -j RETURN
-A FLANNEL-POSTRTG -s 10.244.0.0/16 -d 10.244.0.0/24 -m comment --comment "flanneld masq" -j RETURN
-A FLANNEL-POSTRTG ! -s 10.244.0.0/16 -d 10.244.0.0/24 -m comment --comment "flanneld masq" -j RETURN
-A FLANNEL-POSTRTG -s 10.244.0.0/16 ! -d 224.0.0.0/4 -m comment --comment "flanneld masq" -j MASQUERADE --random-fully
-A FLANNEL-POSTRTG ! -s 10.244.0.0/16 -d 10.244.0.0/16 -m comment --comment "flanneld masq" -j MASQUERADE --random-fully
-A KUBE-LOAD-BALANCER -j KUBE-MARK-MASQ
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
-A KUBE-NODE-PORT -p tcp -m comment --comment "Kubernetes nodeport TCP port for masquerade purpose" -m set --match-set KUBE-NODE-PORT-TCP dst -j KUBE-MARK-MASQ
-A KUBE-POSTROUTING -m comment --comment "Kubernetes endpoints dst ip:port, source ip for solving hairpin purpose" -m set --match-set KUBE-LOOP-BACK dst,dst,src -j MASQUERADE
-A KUBE-POSTROUTING -m mark ! --mark 0x4000/0x4000 -j RETURN
-A KUBE-POSTROUTING -j MARK --set-xmark 0x4000/0x0
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUERADE --random-fully
-A KUBE-SERVICES -s 127.0.0.0/8 -j RETURN
-A KUBE-SERVICES -m comment --comment "Kubernetes service cluster ip + port for masquerade purpose" -m set --match-set KUBE-CLUSTER-IP src,dst -j KUBE-MARK-MASQ
-A KUBE-SERVICES -m addrtype --dst-type LOCAL -j KUBE-NODE-PORT
-A KUBE-SERVICES -m set --match-set KUBE-CLUSTER-IP dst,dst -j ACCEPT
Awkee/Netfilter-IPTables-Diagrams.md
comparing-kube-proxy-modes-iptables-or-ipvs
两个 node 的集群,nginx 启动了两个
$ kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
orange723 Ready control-plane 3h24m v1.34.2 172.22.7.89 <none> Ubuntu 24.04.3 LTS 6.8.0-87-generic docker://29.0.1
orange723-node Ready <none> 30m v1.34.2 172.22.7.90 <none> Ubuntu 24.04.3 LTS 6.8.0-87-generic docker://29.0.1
-----------------------------------------------------------------
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-5846888f49-bd5lx 1/1 Running 0 12m 10.244.1.2 orange723-node <none> <none>
web-5846888f49-fx7bc 1/1 Running 0 3h6m 10.244.0.4 orange723 <none> <none>
master 主机抓取 eth0 网卡
$ tcpdump -s0 -X -nn -i eth0 "tcp port not 22" -w flannel-1-vxlan.pcap --print
能看到在建立连接没有发送数据时,一个容器的包被 udp 包了一层里面是 vxlan,最外层是宿主机正常的 ip 包。
贴下 route -n 的内容后面可以和 host-gw 模式做对比
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.22.15.253 0.0.0.0 UG 100 0 0 eth0
10.244.0.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
10.244.1.0 10.244.1.0 255.255.255.0 UG 0 0 0 flannel.1
100.100.2.136 172.22.15.253 255.255.255.255 UGH 100 0 0 eth0
100.100.2.138 172.22.15.253 255.255.255.255 UGH 100 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
172.22.0.0 0.0.0.0 255.255.240.0 U 100 0 0 eth0
172.22.15.253 0.0.0.0 255.255.255.255 UH 100 0 0 eth0
Ethernet head 默认是 14 bytes Ethernet_frame
flannel vxlan 模式可以参照这篇文章 深入解析容器跨主机网络
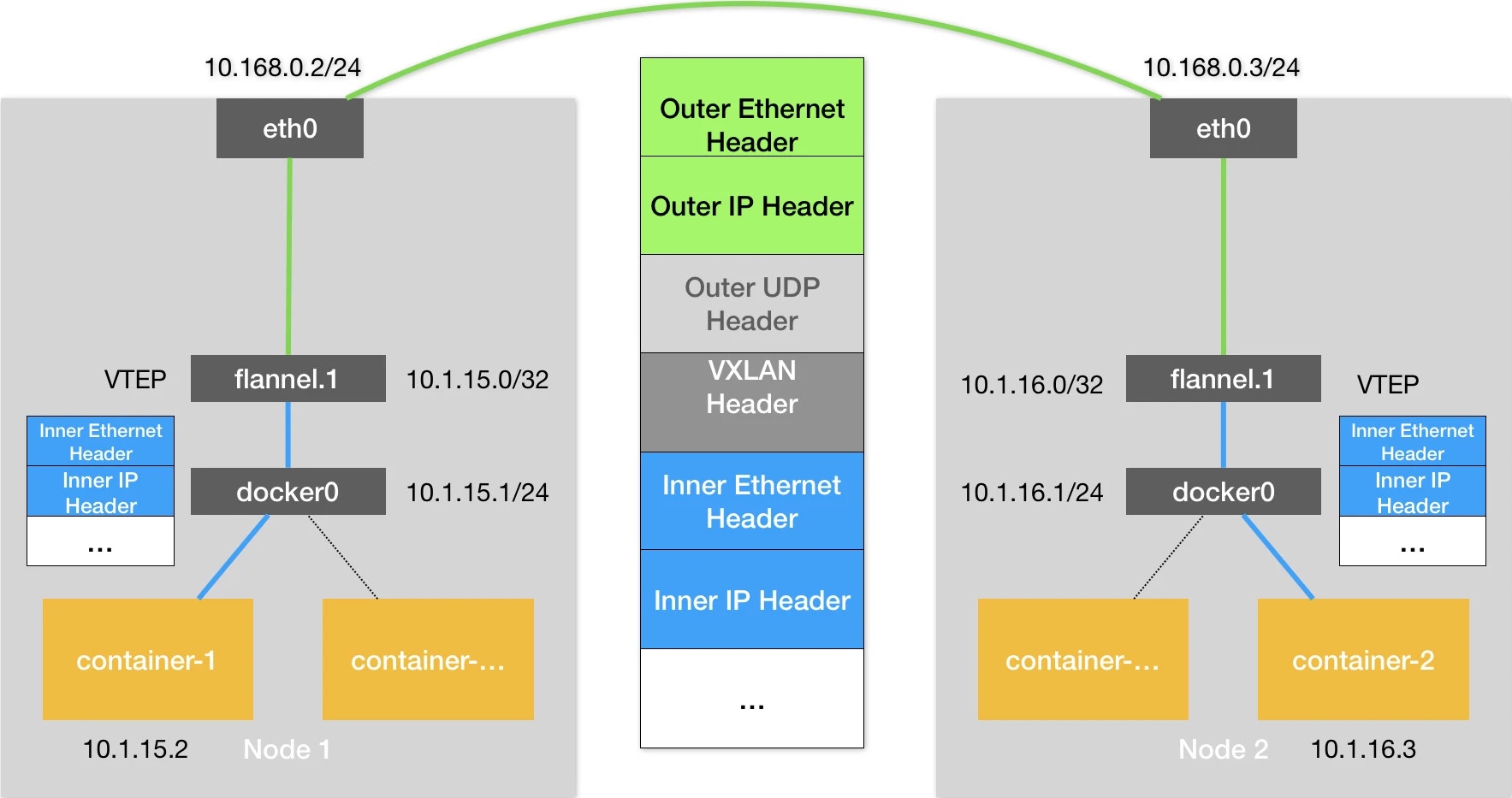
图片来源:深入剖析 Kubernetes
直接修改 kube-flannel namespace 里 kube-flannel-cfg 的 configmap,然后重启 daemonset
$ kubectl get cm kube-flannel-cfg -o yaml|grep host-gw
"Type": "host-gw"
$ kubectl rollout restart ds kube-flannel-ds -n kube-flannel
可以从 log 里看到 Backend type 是 host-gw
I1117 09:10:11.315220 1 main.go:523] Found network config - Backend type: host-gw
在看路由信息,去往另一台机器的 10.244.1.0 网关成了 172.22.7.90 网卡是 eth0,这个 ip 就是另一台 node 的 ip
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.22.15.253 0.0.0.0 UG 100 0 0 eth0
10.244.0.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
10.244.1.0 172.22.7.90 255.255.255.0 UG 0 0 0 eth0
100.100.2.136 172.22.15.253 255.255.255.255 UGH 100 0 0 eth0
100.100.2.138 172.22.15.253 255.255.255.255 UGH 100 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
172.22.0.0 0.0.0.0 255.255.240.0 U 100 0 0 eth0
172.22.15.253 0.0.0.0 255.255.255.255 UH 100 0 0 eth0
这里去 ping 10.244.1.3 另一台的机器上的 pod 发现不通,抓包下,能看到目的 mac 是 ee:ff:ff:ff:ff:ff,云上主机二层网络是不通的,ping 10.244.1.3 走的路由是 10.244.1.0 172.22.7.90 255.255.255.0 UG 0 0 0 eth0 搜索发现 host-gw-in-aliyun,通过在 vpc 自定义路由添加两条规则 本机的 pod cidr 下一跳是这台 ecs,有几个主机添加几个,之后就可以直接连通了。
$ tcpdump -s0 -X -nn -i eth0 "tcp port not 22" -w flannel-1-ping-noresponse.pcap --print

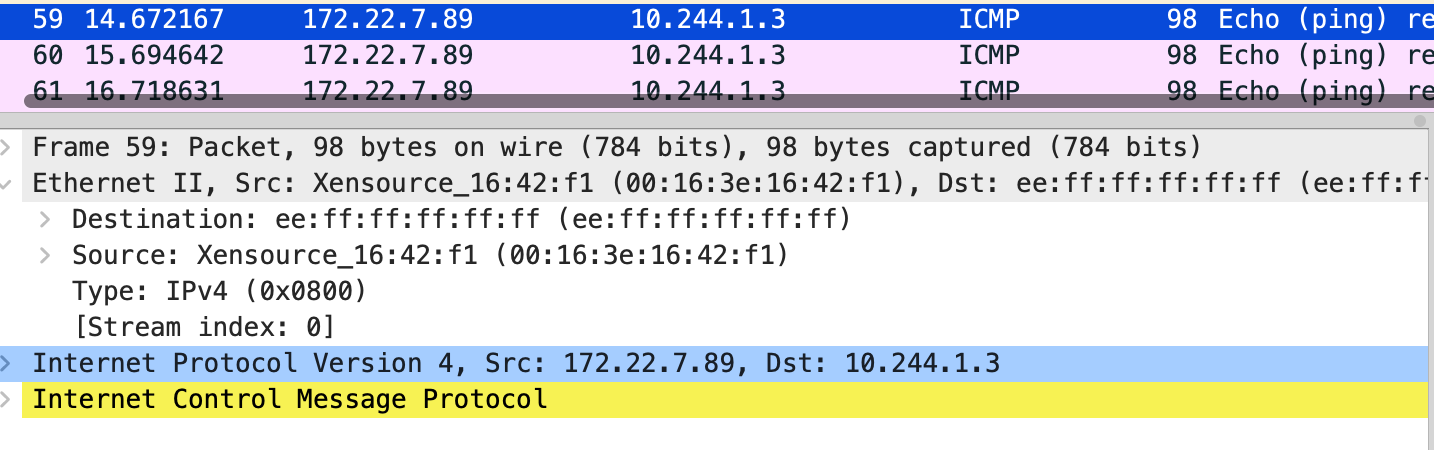
$ arp -n
Address HWtype HWaddress Flags Mask Iface
10.244.0.5 ether 46:33:68:6a:43:bb C cni0
10.244.0.6 ether 46:e3:5c:54:ea:35 C cni0
10.244.0.7 ether 02:dd:96:54:61:7f C cni0
172.22.7.90 ether ee:ff:ff:ff:ff:ff C eth0
172.22.15.253 ether ee:ff:ff:ff:ff:ff C eth0
$ tcpdump -s0 -X -nn -i eth0 "tcp port not 22" -w flannel-1-hostgw-ping.pcap --print

实验流程来自 知识星球:程序员踩坑案例分享
vm-1
$ sudo tcpdump -s0 -X -nn "tcp port 9527" -w vm-1-tcp-send-receive-time-retries.pcap --print
vm-1-tcp-send-receive-time-retries.pcap
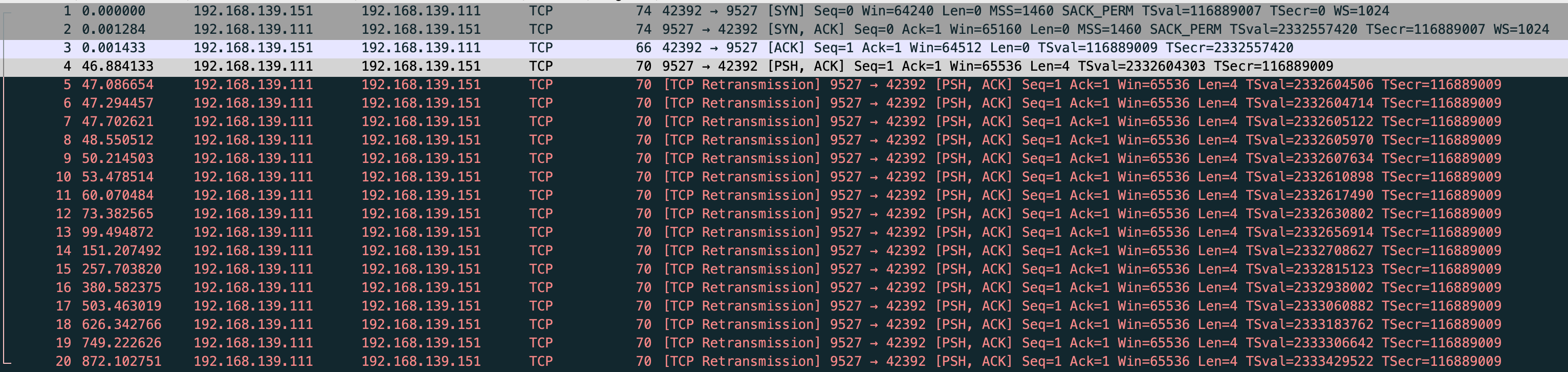
当连接建立好后,vm-2 拦截 vm-1 发的包
$ sudo iptables -A INPUT -p tcp --sport 9527 -j DROP
vm-1 发送数据
$ nc -k -l 192.168.139.111 9527
abc
abc
abc
$ while true;do sudo netstat -anpo|grep 9527|grep -v LISTEN; sleep 1;done
...
tcp 0 4 192.168.139.111:9527 192.168.139.151:37506 ESTABLISHED 303/nc on (3.14/15/0)
tcp 0 4 192.168.139.111:9527 192.168.139.151:37506 ESTABLISHED 303/nc on (2.12/15/0)
tcp 0 4 192.168.139.111:9527 192.168.139.151:37506 ESTABLISHED 303/nc on (1.10/15/0)
tcp 0 4 192.168.139.111:9527 192.168.139.151:37506 ESTABLISHED 303/nc on (0.07/15/0)
tcp 0 4 192.168.139.111:9527 192.168.139.151:37506 ESTABLISHED 303/nc on (0.00/15/0)
tcp 0 4 192.168.139.111:9527 192.168.139.151:37506 ESTABLISHED 303/nc on (0.00/15/0)
能看到重传了 15 次,但在抓包里看到了 16 个重传包
tcp_retries2 - INTEGER
This value influences the timeout of an alive TCP connection, when RTO retransmissions remain unacknowledged. Given a value of N, a hypothetical TCP connection following exponential backoff with an initial RTO of TCP_RTO_MIN would retransmit N times before killing the connection at the (N+1)th RTO.
The default value of 15 yields a hypothetical timeout of 924.6 seconds and is a lower bound for the effective timeout. TCP will effectively time out at the first RTO which exceeds the hypothetical timeout. If tcp_rto_max_ms is decreased, it is recommended to also change tcp_retries2.
RFC 1122 recommends at least 100 seconds for the timeout, which corresponds to a value of at least 8.
第一个包其实不算做重传,而是对端在 rto 时间没有回复,然后触发重传
47.086654-46.884133=0.202521
$ sudo sysctl net.ipv4.tcp_retries2
net.ipv4.tcp_retries2 = 15
文中对 RTT 和 RTO 的描述
RTT(Round Trip Time):指一个数据包从发出去到回来的时间
RTO(Retransmission TimeOut):指的是重传超时的时间
linux 中有 TCP_RTO_MIN 内核参数
tcp_rto_min_us - INTEGER
Minimal TCP retransmission timeout (in microseconds). Note that the rto_min route option has the highest precedence for configuring this setting, followed by the TCP_BPF_RTO_MIN and TCP_RTO_MIN_US socket options, followed by this tcp_rto_min_us sysctl.
The recommended practice is to use a value less or equal to 200000 microseconds.
Possible Values: 1 - INT_MAX
Default: 200000
$ sudo sysctl net.ipv4.tcp_rto_min_us
net.ipv4.tcp_rto_min_us = 200000
具体的 rto 是根据 TCP_RTO_MIN 计算出的,也能查看到
$ sudo ss -tip|grep -A 1 9527
ESTAB 0 0 192.168.139.111:9527 192.168.139.151:57060 users:(("nc",pid=303,fd=4))
cubic wscale:10,10 rto:201 rtt:0.078/0.039 mss:1448 pmtu:1500 rcvmss:536 advmss:1448 cwnd:10 segs_in:2 send 1.49Gbps lastsnd:21909 lastrcv:21909 lastack:21909 pacing_rate 2.97Gbps delivered:1 app_limited rcv_space:14480 rcv_ssthresh:64088 minrtt:0.078 snd_wnd:64512
当从 vm-1 发送数据到 vm-2 再次查看 rto,重试后会增加的
$ sudo ss -tip|grep -A 1 9527
ESTAB 0 4 192.168.139.111:9527 192.168.139.151:57060 users:(("nc",pid=303,fd=4))
cubic wscale:10,10 rto:25728 backoff:7 rtt:0.078/0.039 ato:40 mss:1448 pmtu:1500 rcvmss:536 advmss:1448 cwnd:1 ssthresh:7 bytes_sent:36 bytes_retrans:32 bytes_received:4 segs_out:18 segs_in:11 data_segs_out:9 data_segs_in:9 send 149Mbps lastsnd:11529 lastrcv:42622 lastack:16135 pacing_rate 297Mbps delivered:1 app_limited busy:38299ms unacked:1 retrans:1/8 lost:1 rcv_space:14480 rcv_ssthresh:64088 minrtt:0.078 snd_wnd:64512
$ sudo tcpdump -s0 -X -nn "tcp port 9527" -w vm-1-tcp-send-receive-dupack3-wrong.pcap --print
vm-1-tcp-send-receive-dupack3-wrong.pcap
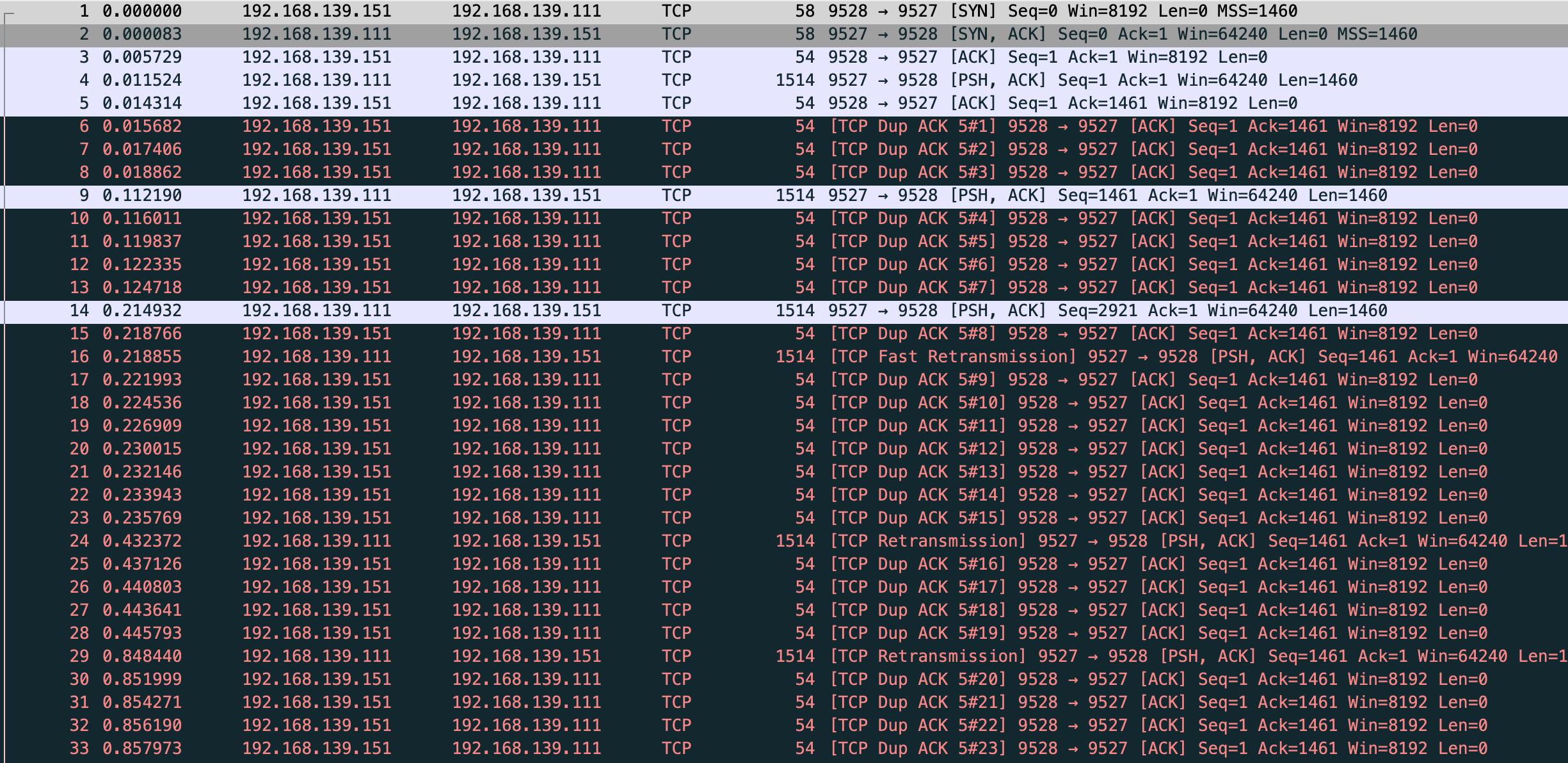
确实能看到 TCP Fast Retransmission 但是和文章中确不一样,vm-1 的数据没发完 vm-2 就在发 TCP Dup ACK,在 fast 前已经发了 7 个 dup ack,根据 net.ipv4.tcp_reordering 默认是3,也就是发 3 次 dup ack 才会快速重传,一开始猜测是我本地两台虚拟机传输速度太快的原因,这里贴下 vm-1 server 和 vm-2 client 的代码
测试前需要在 vm-2 drop 发送给 vm-1 的 rst 包
$ sudo iptables -A OUTPUT -p tcp --tcp-flags RST RST --dport 9527 -j DROP
vm-1
import socket
import time
def start_server(host, port, backlog):
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind((host, port))
server.listen(backlog)
client, _ = server.accept()
client.setsockopt(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1) # 禁用 Nagle 算法
client.sendall(b"a" * 1460)
time.sleep(0.1) # 避免协议栈合并包的方式,不严谨但是凑合能工作
client.sendall(b"b" * 1460)
time.sleep(0.1)
client.sendall(b"c" * 1460)
time.sleep(0.1)
client.sendall(b"d" * 1460)
time.sleep(0.1)
client.sendall(b"e" * 1460)
time.sleep(0.1)
client.sendall(b"f" * 1460)
time.sleep(0.1)
client.sendall(b"g" * 1460)
time.sleep(10000)
if __name__ == '__main__':
start_server('192.168.139.111', 9527, 8)
后面将 vm-1 server 的 time.sleep(0.1) 注释,保持 iptables 规则,重新测试
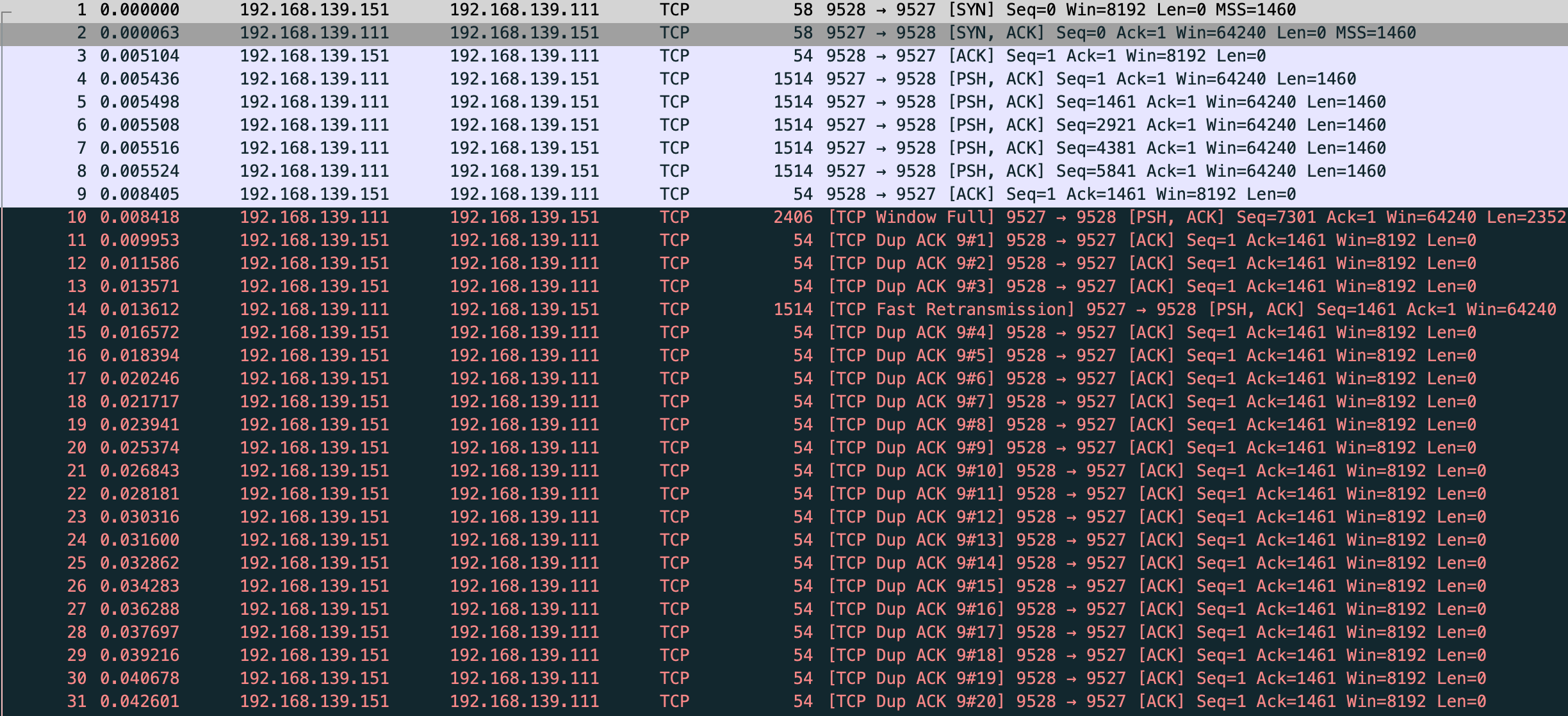
$ sudo tcpdump -s0 -X -nn "tcp port 9527" -w vm-1-tcp-send-receive-dupack3.pcap --print
vm-1-tcp-send-receive-dupack3.pcap
能看到这三个 TCP Dup ACK 的序列号全是 1566486280
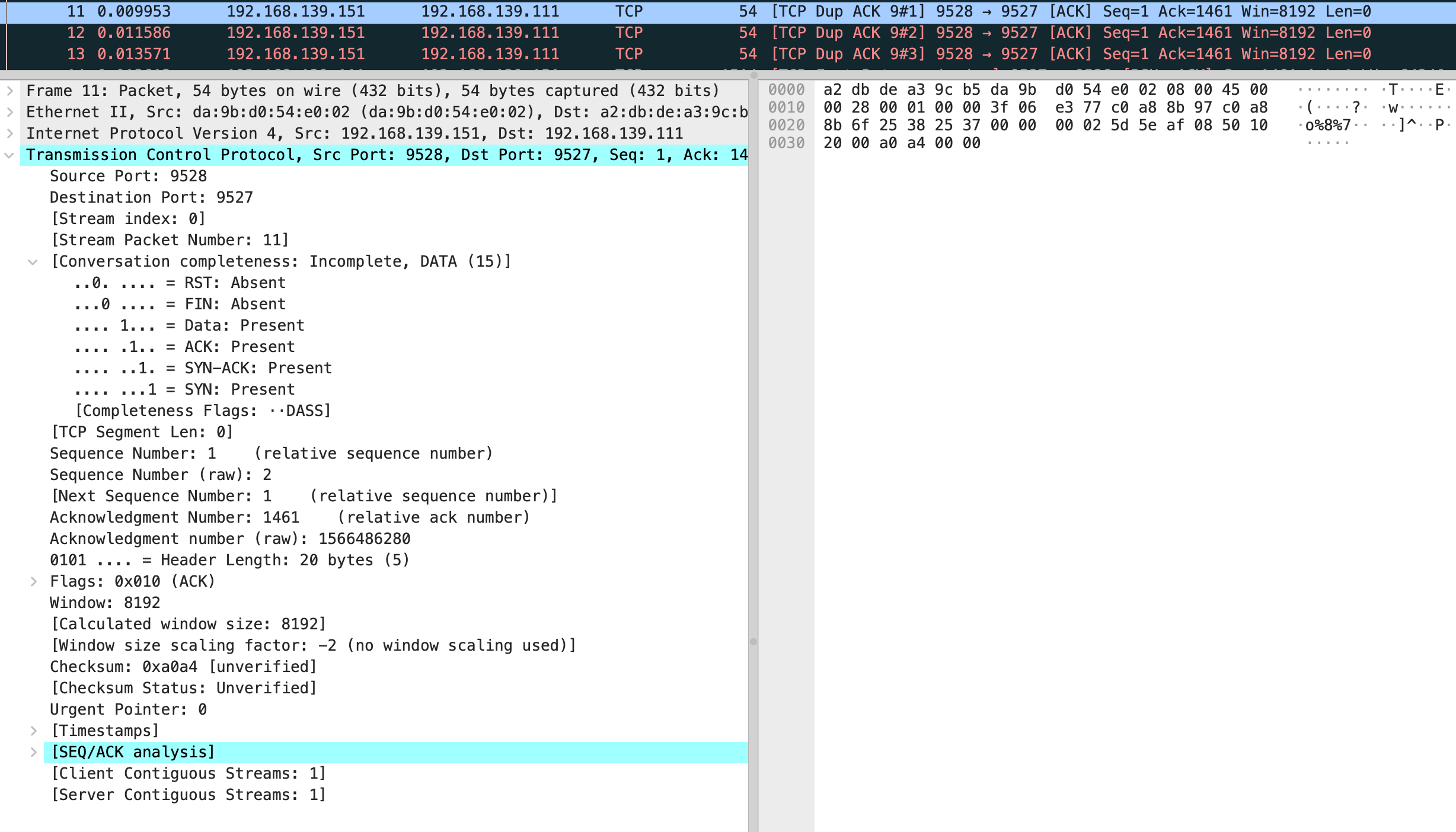
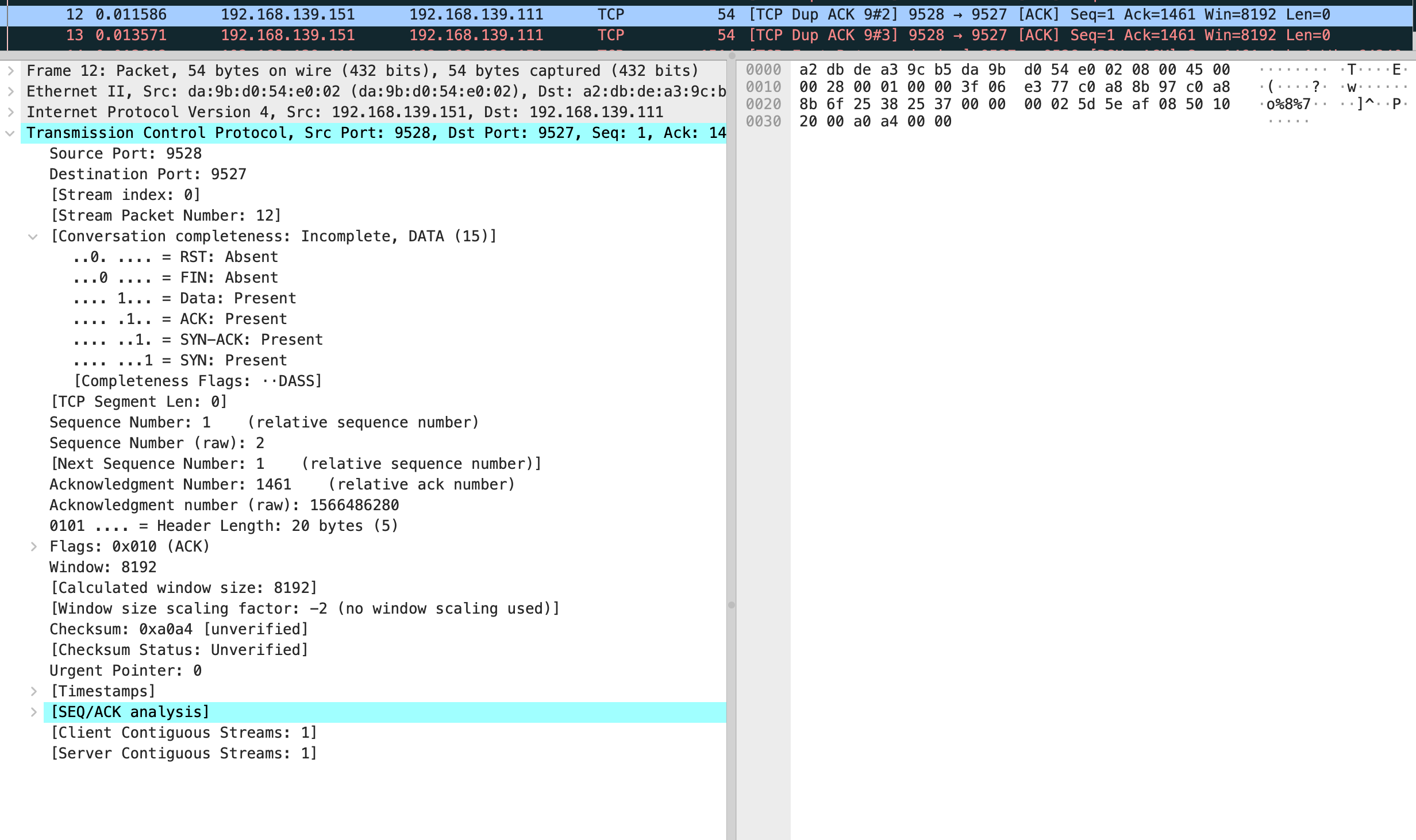
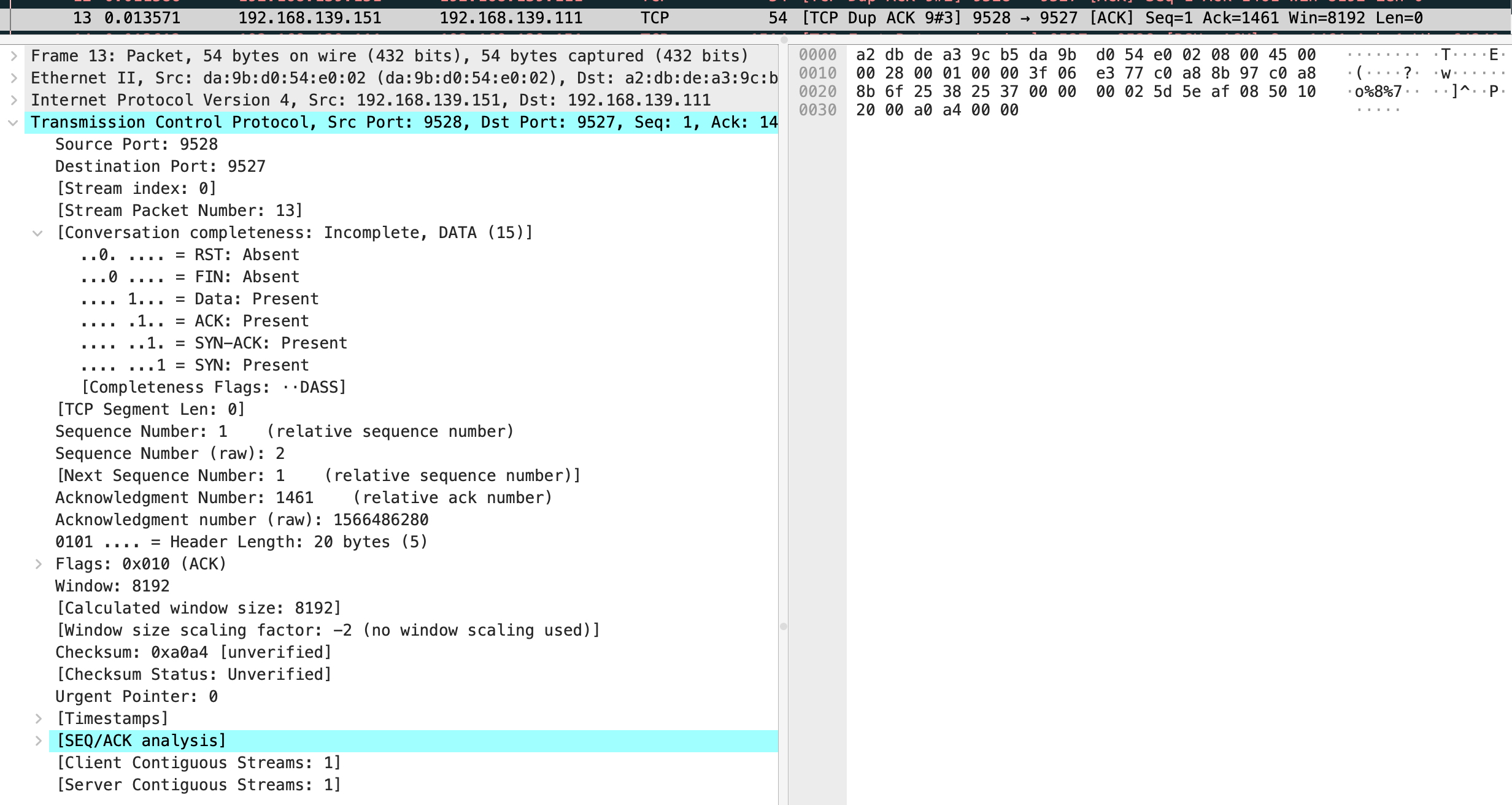
然后快速重传发送了 seq 为 1566486280 的包,这里和文中有一些不一样,我的抓包显示第 9 个包是 vm-2 回复了 ack 对应第 4 个发送数据的包。
假如这时你断开 vm-1 的 server,你会发现 vm-1 和 vm-2 本来为 established 的状态变为 FIN1,但是 vm-1 还是在继续重传此时是基于 rto 的重传会发送 15 次,很 TCP。
$ sudo netstat -anpo|grep -E "Recv|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 0 192.168.139.111:9527 0.0.0.0:* LISTEN 698/python3 off (0.00/0/0)
tcp 0 8760 192.168.139.111:9527 192.168.139.151:9528 ESTABLISHED 698/python3 on (108.19/12/0)
$ sudo netstat -anpo|grep -E "Recv|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 8761 192.168.139.111:9527 192.168.139.151:9528 FIN_WAIT1 - on (102.22/12/0)
$ sudo netstat -anpo|grep -E "Recv|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 8761 192.168.139.111:9527 192.168.139.151:9528 FIN_WAIT1 - on (82.74/12/0)
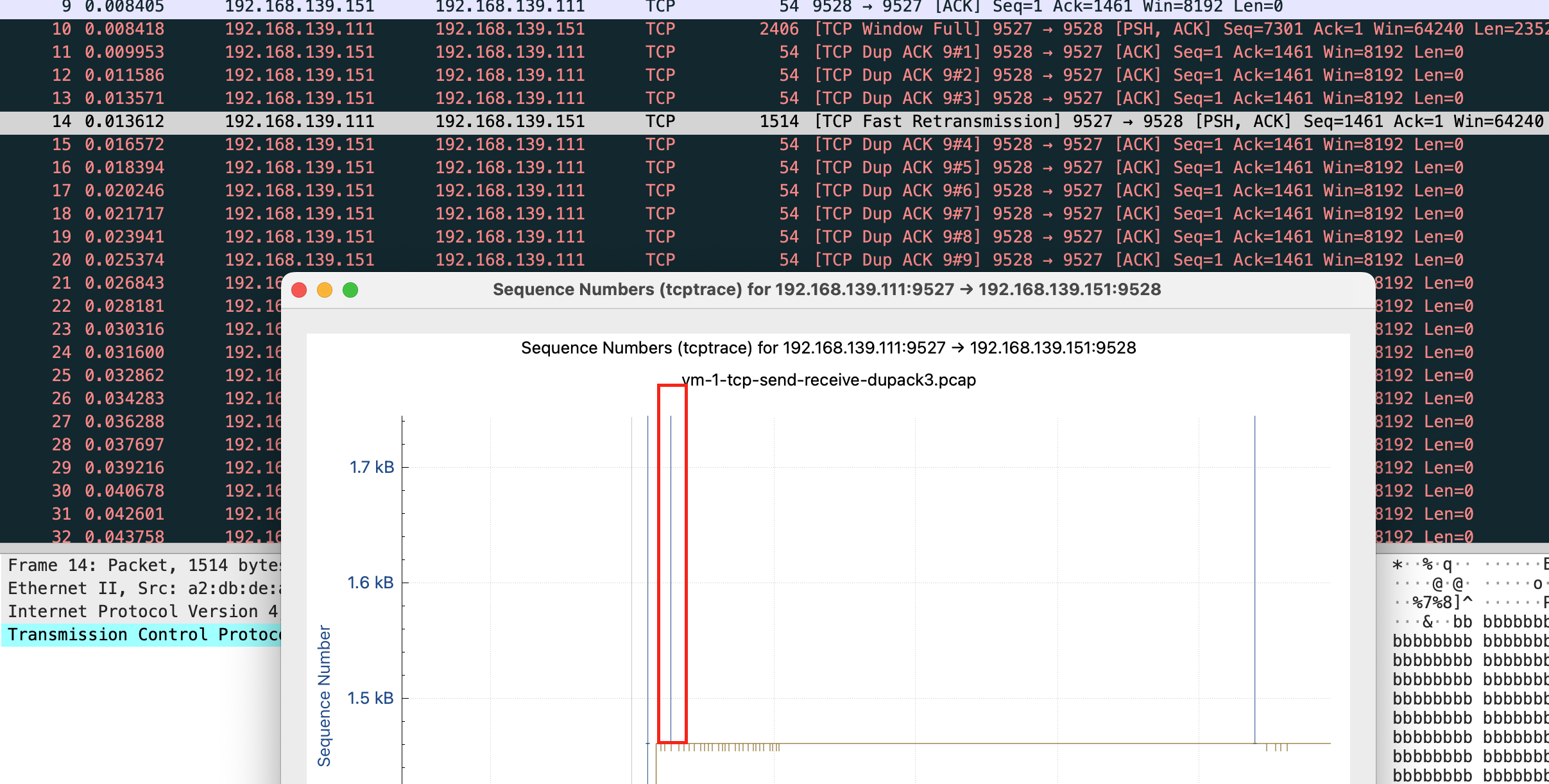
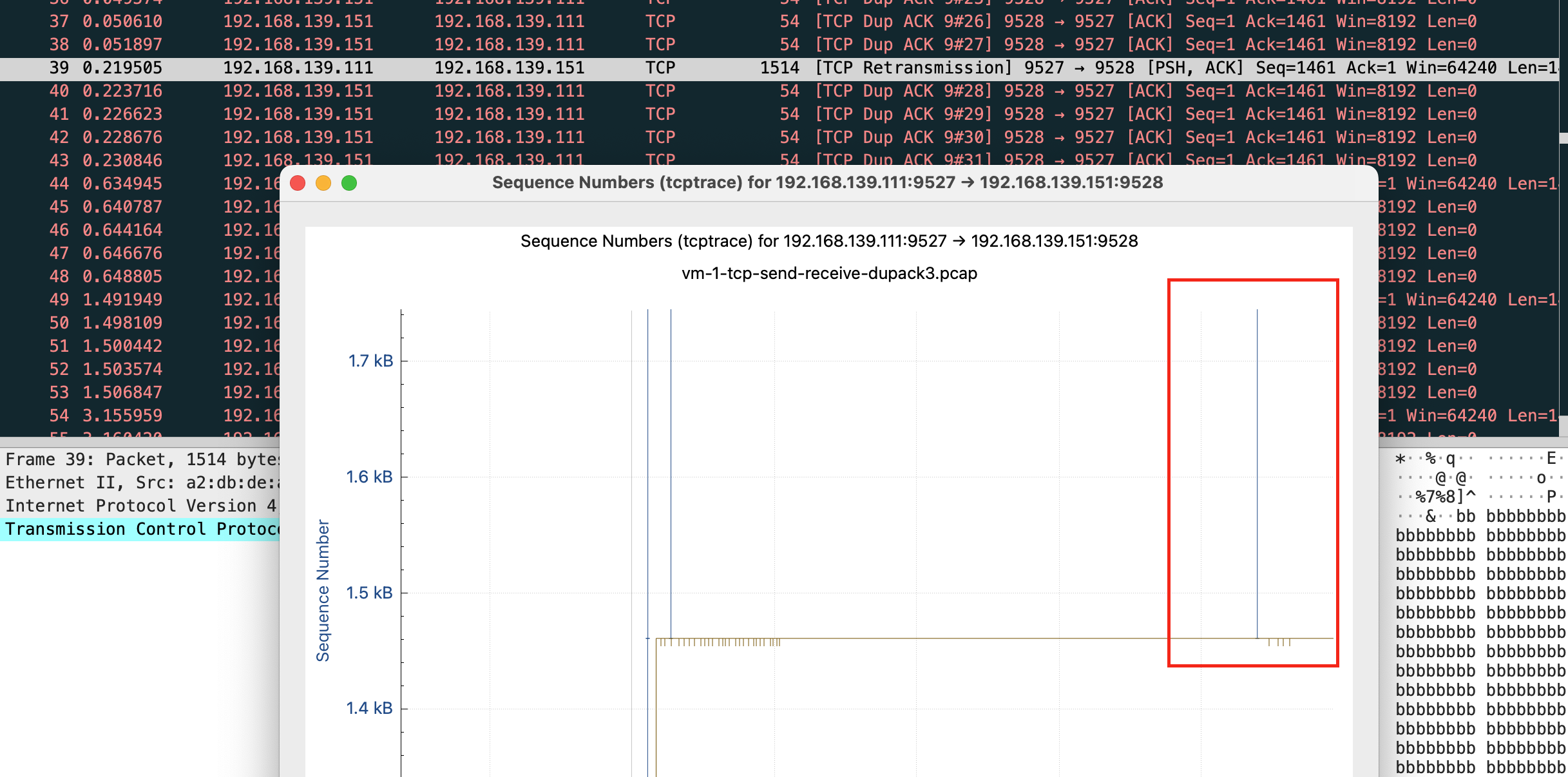
这里能看到快速重传和基于时间重传的差距
快速
基于时间
在测试下,修改 net.ipv4.tcp_reordering
$ sudo sysctl net.ipv4.tcp_reordering
net.ipv4.tcp_reordering = 3
$ sudo sysctl -w net.ipv4.tcp_reordering=1
net.ipv4.tcp_reordering = 1
$ sudo tcpdump -S -s0 -X -nn "tcp port 9527" -w vm-1-tcp-send-receive-dupack1.pcap --print
vm-1-tcp-send-receive-dupack1.pcap

$ sudo tcpdump -S -s0 -X -nn "tcp port 9527" -w vm-1-tcp-send-receive-scak.pcap --print
vm-1-tcp-send-receive-scak.pcap
vm-2 的 iptables 规则还是要保持
vm-1
$ nc -k -l 192.168.139.111 9527
vm-2
import time
from scapy.all import *
from scapy.layers.inet import *
def main():
ip = IP(dst="192.168.139.111")
myself_seq = 1
tcp = TCP(sport=9528, dport=9527, flags='S', seq=myself_seq, options=[("SAckOK", '')])
print("send SYN, seq=0")
resp = sr1(ip/tcp, timeout=2)
if not resp:
print("recv timeout")
return
resp_tcp = resp[TCP]
if 'SA' in str(resp_tcp.flags):
recv_seq = resp_tcp.seq
recv_ack = resp_tcp.ack
print(f"received SYN, seq={recv_seq}, ACK={recv_ack}")
myself_seq += 1
send_ack = recv_seq + 1
tcp = TCP(sport=9528, dport=9527, flags='A', seq=myself_seq, ack=send_ack)
print(f"send ACK={send_ack}")
send(ip/tcp)
# 特意注释掉,让发的数据有空洞
# send data
# payload = b"a" * 10
# tcp = TCP(sport=9528, dport=9527, flags='A', seq=myself_seq, ack=send_ack)
# send(ip/tcp/payload)
myself_seq += 10
payload = b"b" * 10
tcp = TCP(sport=9528, dport=9527, flags='A', seq=myself_seq, ack=send_ack)
send(ip/tcp/payload)
myself_seq += 10
# 特意注释掉,让发的数据有空洞
# payload = b"c" * 10
# tcp = TCP(sport=9528, dport=9527, flags='A', seq=myself_seq, ack=send_ack)
# send(ip/tcp/payload)
myself_seq += 10
payload = b"d" * 10
tcp = TCP(sport=9528, dport=9527, flags='A', seq=myself_seq, ack=send_ack)
send(ip/tcp/payload)
elif 'R' in str(resp_tcp.flags):
print(f"received RST")
else:
print("received different TCP flags")
time.sleep(100)
if __name__ == "__main__":
main()
这时 vm-2 是作为发送端,原文有些没法理解,问了 gpt 给出了关于发送数据空洞和 vm-1 发送的 sack 选项
“让数据有空洞”到底是什么意思(网络上发生了什么)
普通 TCP 顺序数据到达时,接收端按序累计确认(cumulative ACK),ACK 的值是最后连续无缺口字节的下一个序号。
当你不发送某些中间段(比如注释掉的 a、c),但发送了其后的段 b、d 时,接收端会收到 “out-of-order” 数据:它能接收并缓存 b、d,但不能推进累计 ACK,因为 a 缺失阻断了连续序列。
若接收端支持 SACK,它会在返回的 ACK 中带上 SACK 选项,告知发送端“我已经收到了哪些非连续的块(例如 [seq_b, seq_b+9], [seq_d, seq_d+9])”,从而允许发送端只重传缺失的块(a, c),而不用重传整条流。
简短:你制造的“空洞”就是模拟中间包丢失 / 未发送 的场景,用来触发 SACK 的行为(接收端用 SACK 报告已收到的非连续数据块)。
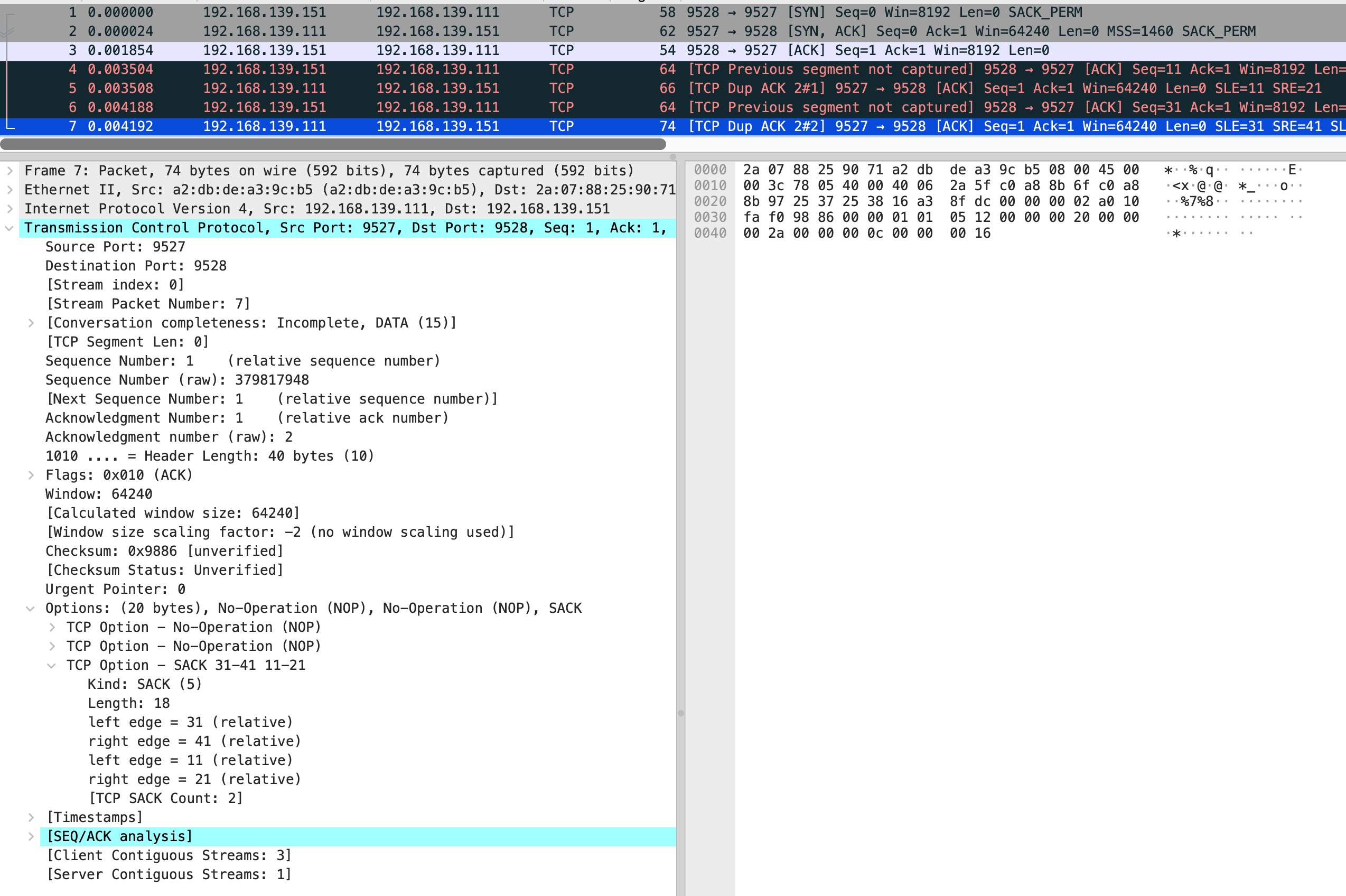
结合抓包来看,vm-2 发送了第 4 个包 是个 ack,seq number 是 11,next seq number 应该是 21,第 6 个包 seq number 32,next seq number 是 41
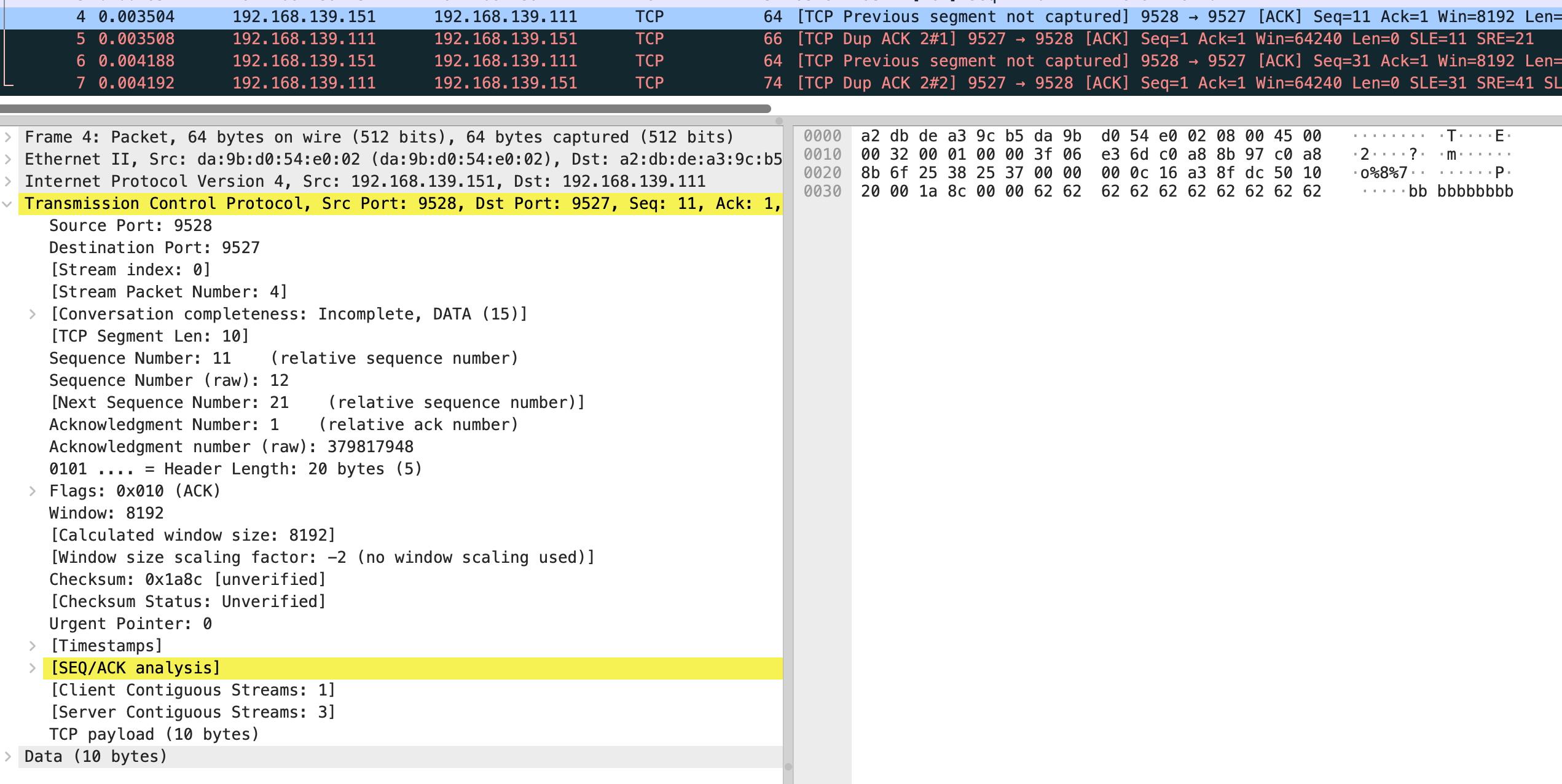
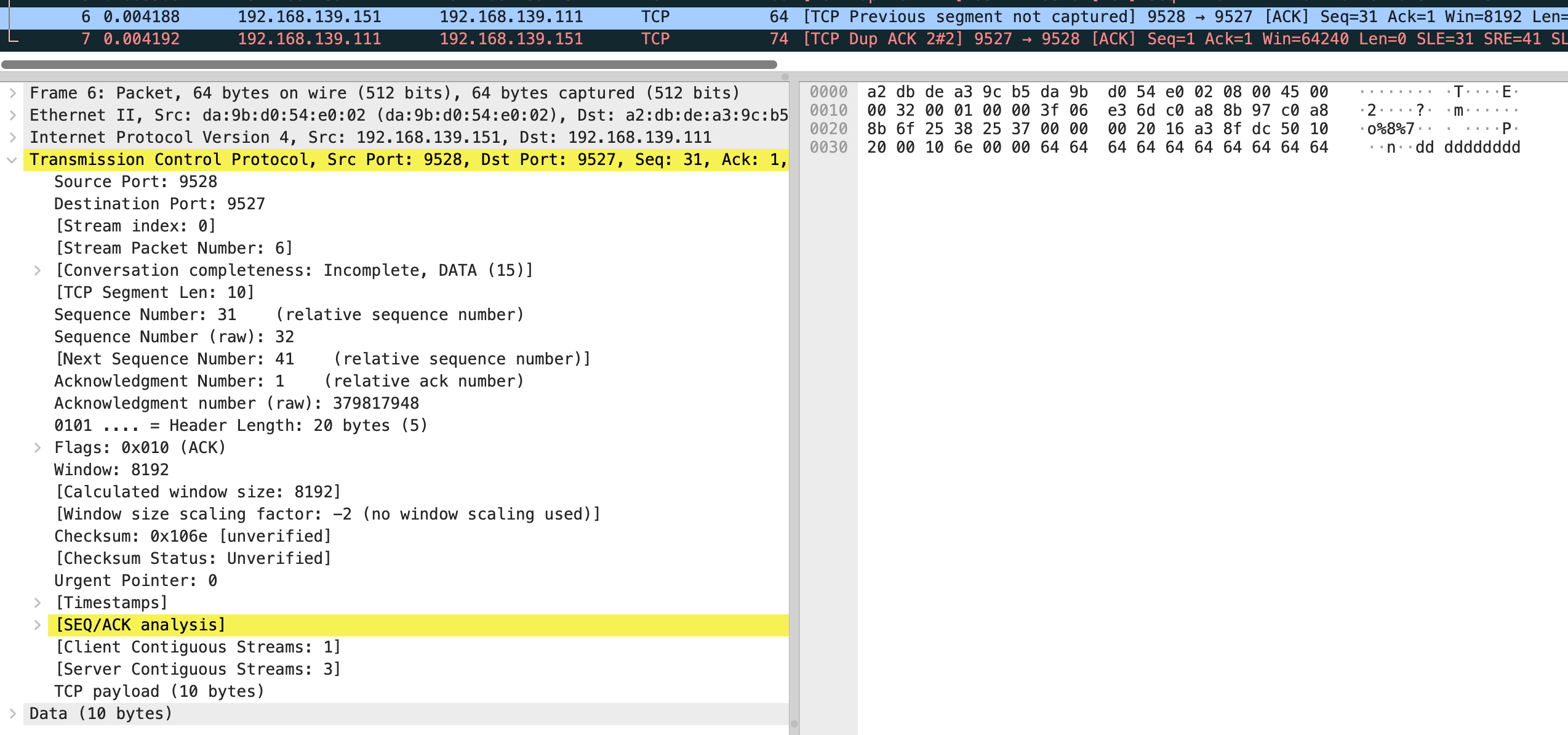
在分别看 5 和 7 包的 sack
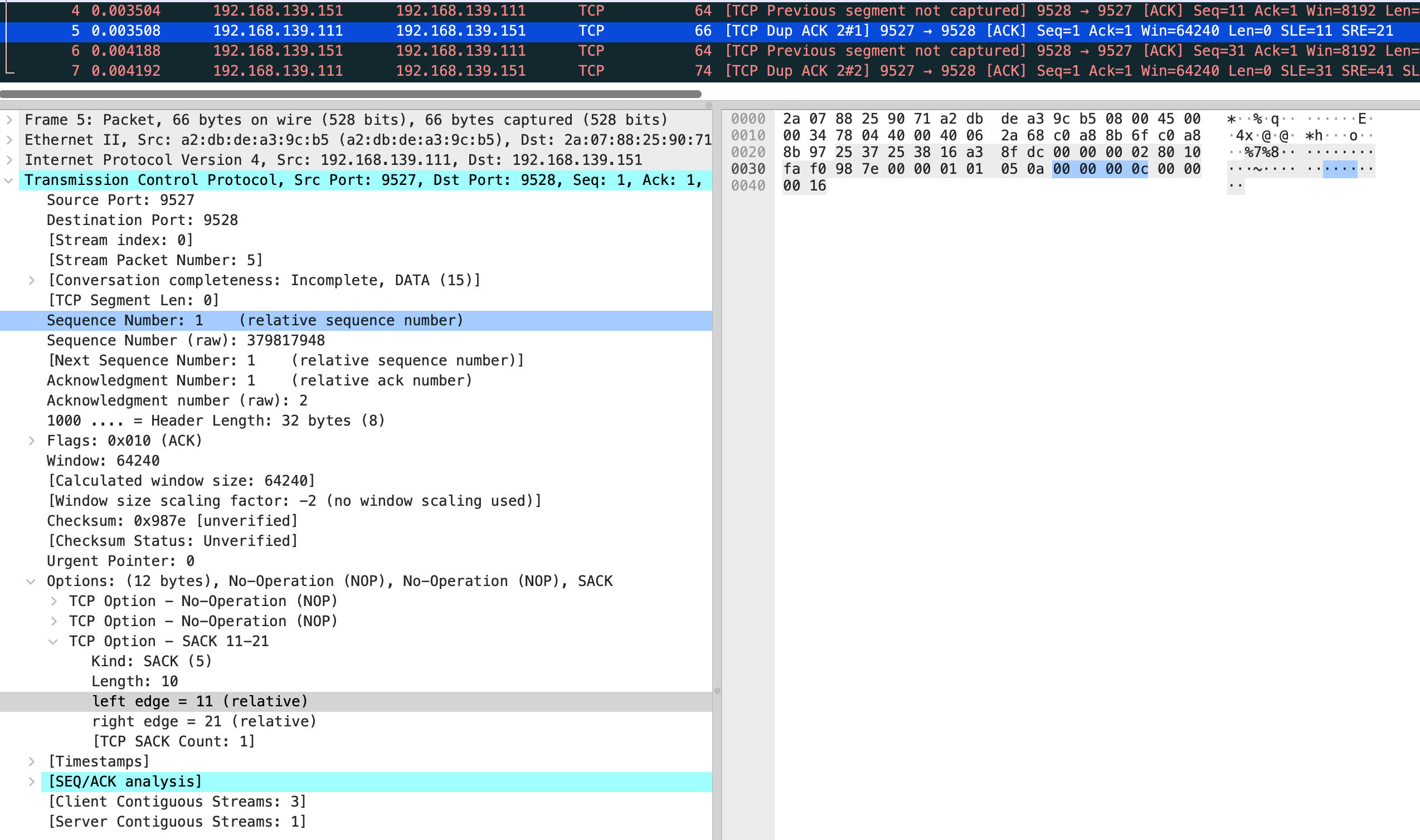
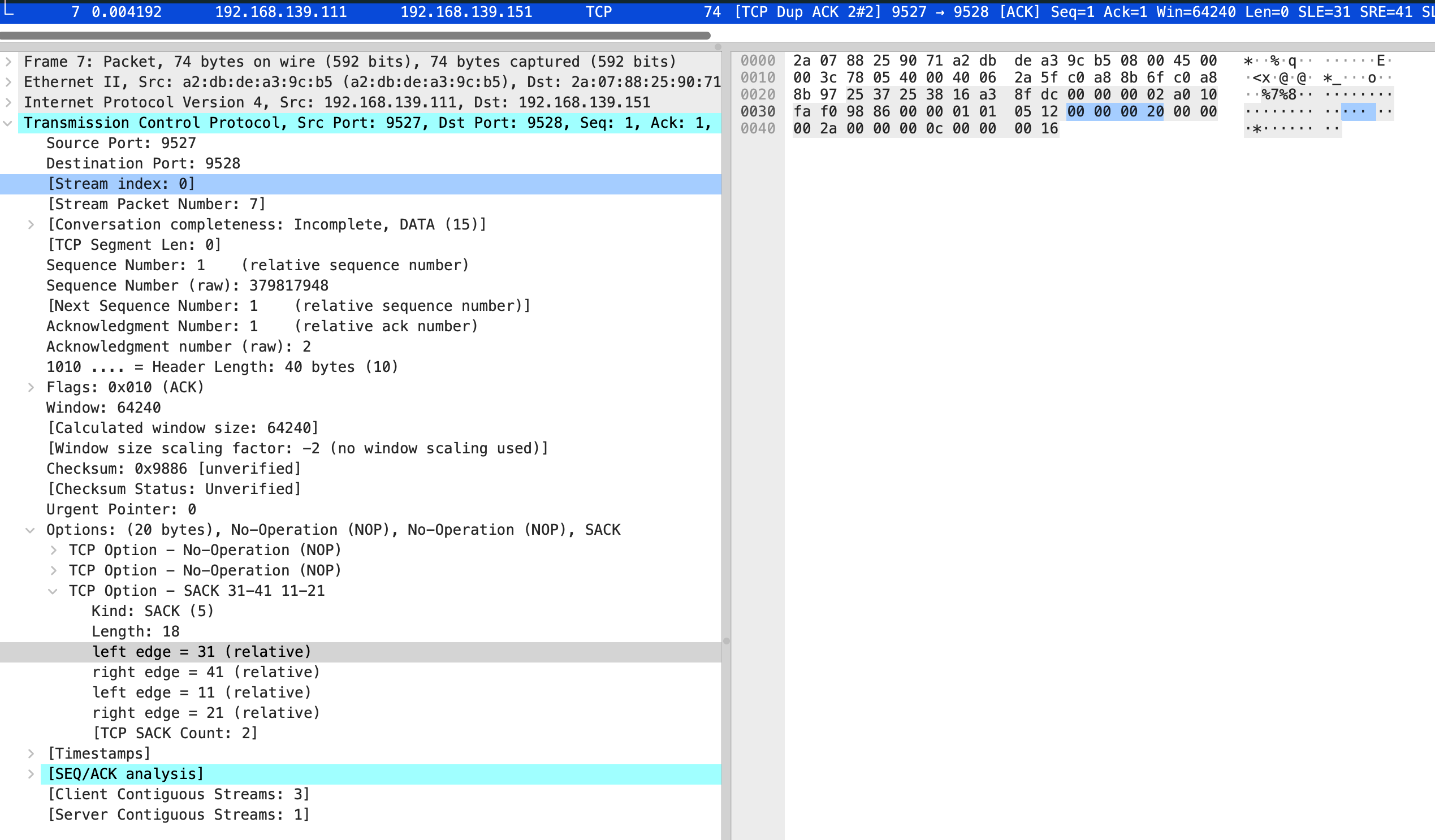
也就是缺失 0-10 和 21-30 的包,需要 vm-1 重新发送。
这部分后面如果碰到不是模拟的场景,和缺失的场景对比下会更好。
$ sudo tcpdump -S -s0 -X -nn "tcp port 9527" -w vm-1-tcp-window-scale.pcap --print
不读数据的服务端和循环发送的客户端代码
vm-1
import socket
import time
def start_server(host, port, backlog):
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind((host, port))
server.listen(backlog)
client, _ = server.accept()
time.sleep(10000)
if __name__ == '__main__':
start_server('192.168.139.111', 9527, 8)
-----------------------------------------------------------------
vm-2
import socket
import time
def start_client(host, port):
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect((host, port))
client.setblocking(False)
send_size = 0
data = b"a" * 100000
while True:
try:
size = client.send(data)
if size > 0:
send_size += size
print(f"send_size: {send_size}")
except BlockingIOError:
time.sleep(0.1)
pass
if __name__ == '__main__':
start_client('192.168.139.111', 9527)
能看到 vm-2 发的包基本都超过 mtu 大小,检查 generic-segmentation-offload/generic-receive-offload/tcp-segmentation-offload,vm-1 和 vm-2 是一样的。
$ sudo ethtool -k eth0|grep -E "generic-segmentation-offload|generic-receive-offload"
generic-segmentation-offload: on
generic-receive-offload: off
$ sudo ethtool -k eth0|grep tcp-segmentation-offload
tcp-segmentation-offload: on
gpt 解释如下,简单来说会把包合并发送
| 特性 | 方向 | 执行位置 | 含义 | 是否硬件相关 |
|---|---|---|---|---|
| TSO (TCP Segmentation Offload) | 发送 | 网卡硬件 | TCP 大包分片由网卡完成 | ✅ 硬件 |
| GSO (Generic Segmentation Offload) | 发送 | 内核/驱动 | 软件模拟 TSO 的功能 | ⚙️ 软件 |
| GRO (Generic Receive Offload) | 接收 | 内核/驱动 | 把多个包合并成一个大的 | ⚙️ 软件 |
同时能看到 vm-1 的 Recv-Q 和 vm-2 的 Send-Q 都有堆积,这里恰好能和 TCP 连接的建立 中最后的 nginx 实验部分关联上,云上的 nginx 发送给 vm-2 数据但 vm-2 还没回 ack,Send-Q 会有数值
此代码是 vm-2 一直发送,vm-1 接收但不读取数据
vm-1
$ sudo netstat -anpo|grep -E "Recv|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 0 192.168.139.111:9527 0.0.0.0:* LISTEN 335/python3 off (0.00/0/0)
tcp 123976 0 192.168.139.111:9527 192.168.139.151:45010 ESTABLISHED 335/python3 off (0.00/0/0)
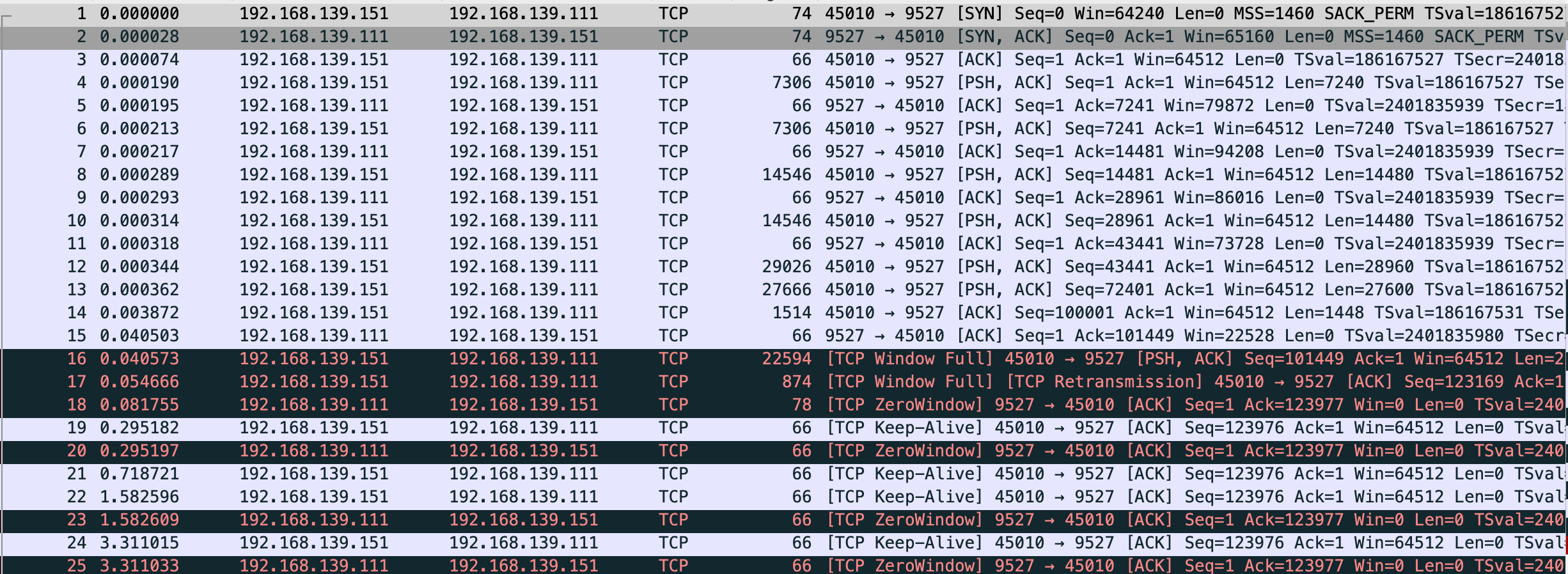
-----------------------------------------------------------------
vm-2
$ sudo netstat -anpo|grep -E "Recv|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 706624 192.168.139.151:45010 192.168.139.111:9527 ESTABLISHED 295/python3 probe (3.53/0/0)
两边机器都关闭
$ sudo ethtool -K eth0 gso off
$ sudo ethtool -K eth0 tso off
$ sudo tcpdump -S -s0 -X -nn "tcp port 9527" -w vm-1-tcp-window-scale-disable-gso-tso.pcap --print
vm-1-tcp-window-scale-disable-gso-tso.pcap
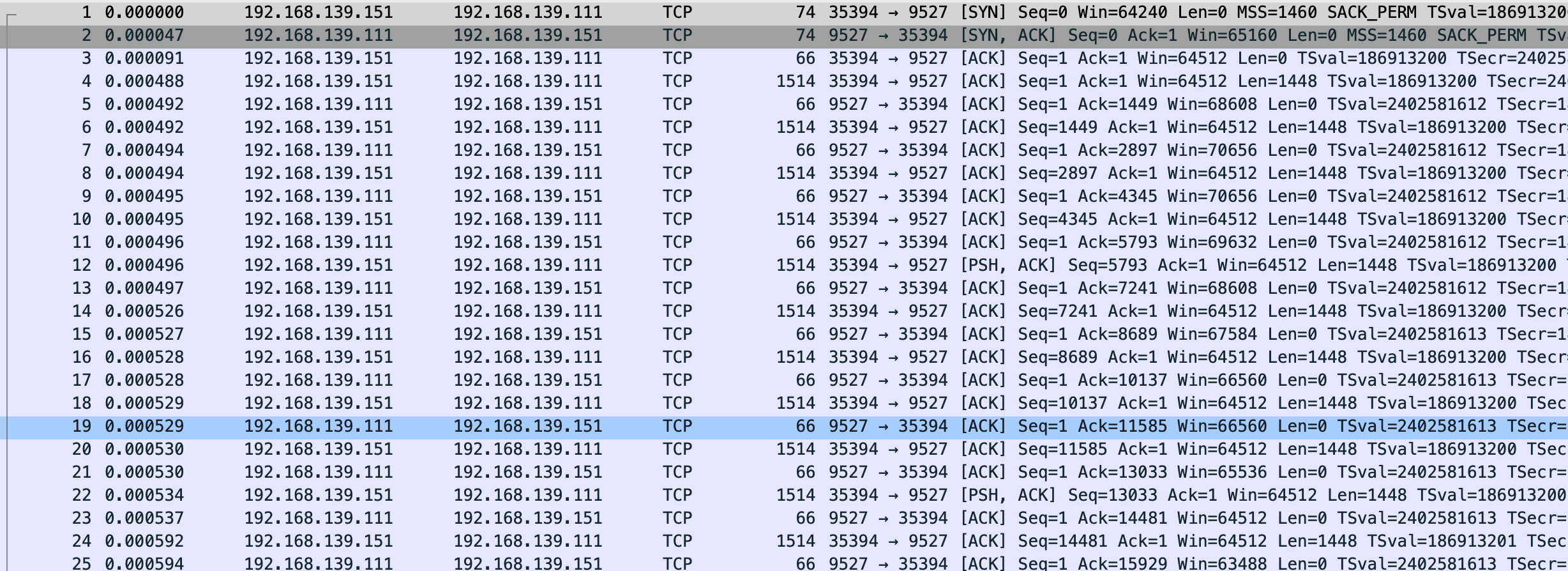
这回变正常了,数据该堆积还是堆积,不过有一点 关闭 gso/tso 后抓的包比未关闭要多将近 100 个左右,效率较低。
$ sudo tcpdump -S -s0 -X -nn "tcp port 9527" -w vm-1-tcp-window-scale-recv.pcap --print
vm-1-tcp-window-scale-recv.pcap
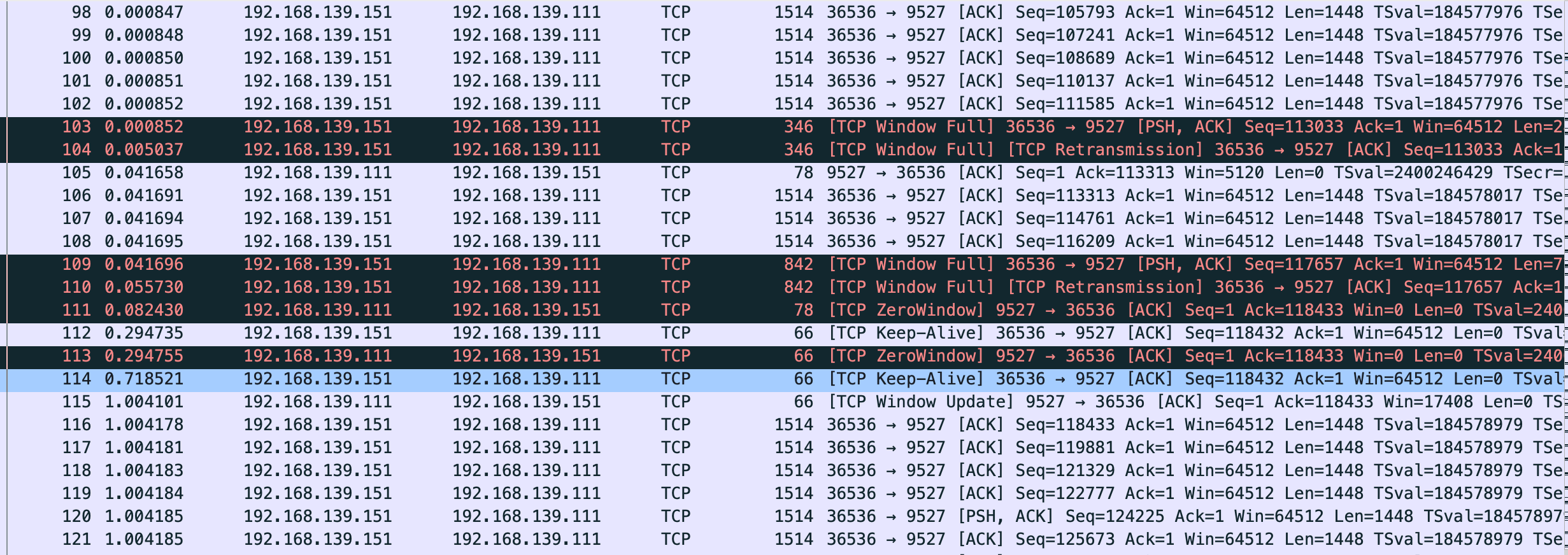
变更服务端代码
import socket
import time
def start_server(host, port, backlog):
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind((host, port))
server.listen(backlog)
client, _ = server.accept()
client.setsockopt(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1) # 禁用 Nagle 算法
while True:
for i in range(5):
client.recv(4096)
time.sleep(1)
if __name__ == '__main__':
start_server('192.168.139.111', 9527, 8)
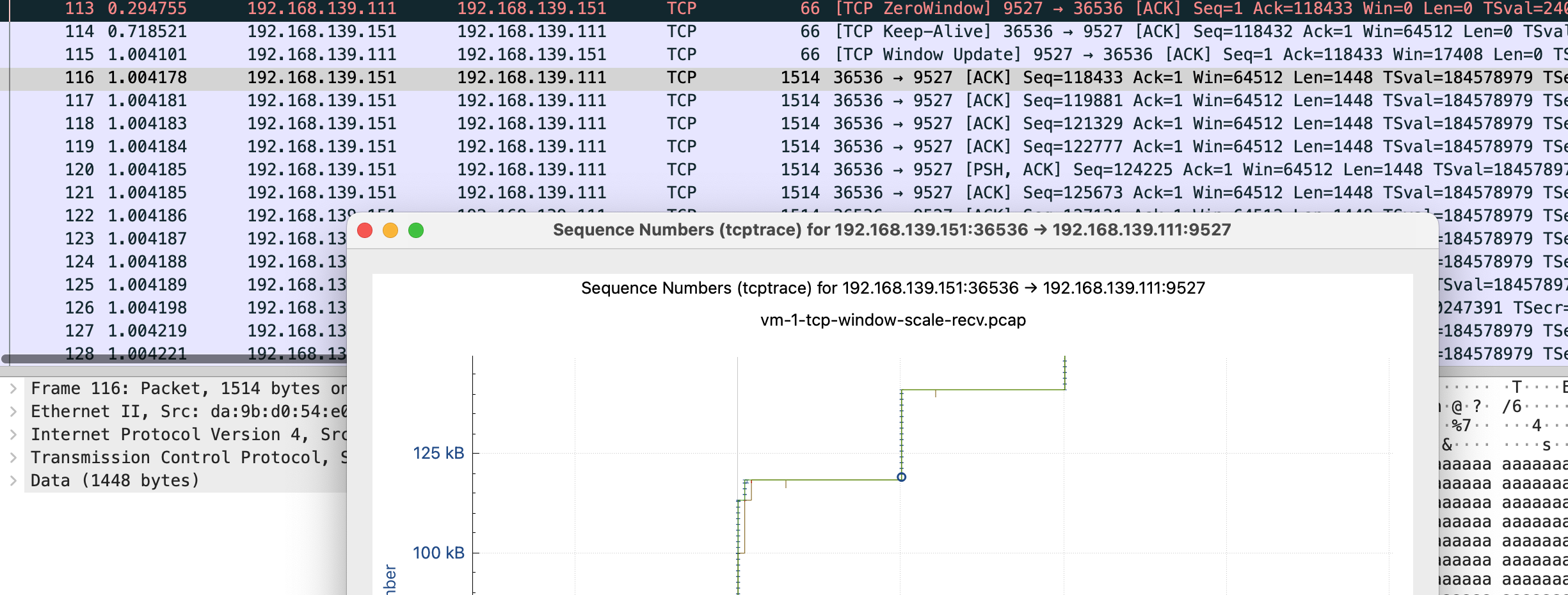
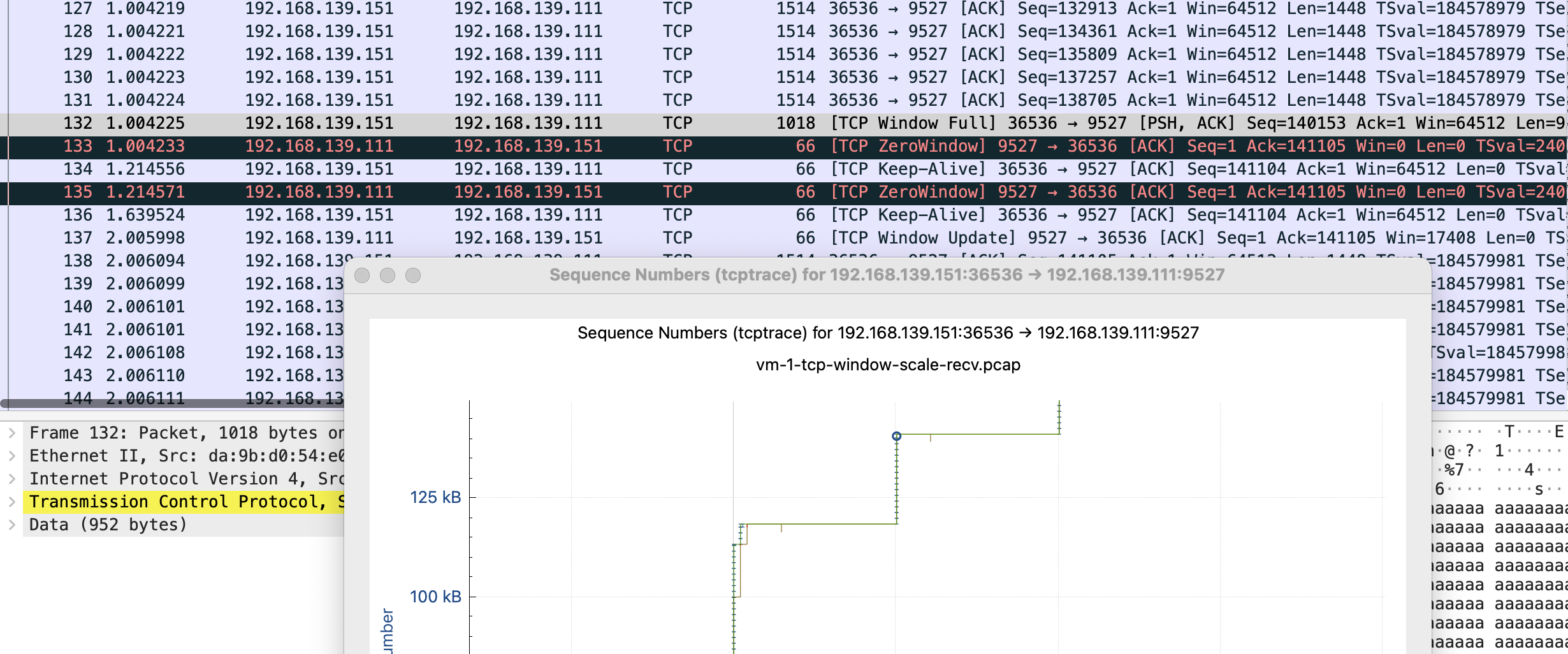
感觉这个图表有助于理解,这里放下原文
这里简单解释下这个图,X 轴是时间,Y 轴是 Sequence Number,绿色线是接收方的 window size,蓝色线是发送的包(捕获到的包),黄色的线是 ACK 过的 Sequence Number 值。那么从图上就可以看出来,每当接收方的 window size 增大的时候,立即就有包发送出去了。当 window size 为 0(线平了)的时候,发送立即就停止了。所以这个图告诉我们这个传输是接收方的瓶颈,是接收方通过 window size 的关闭对发送端进行了限流。
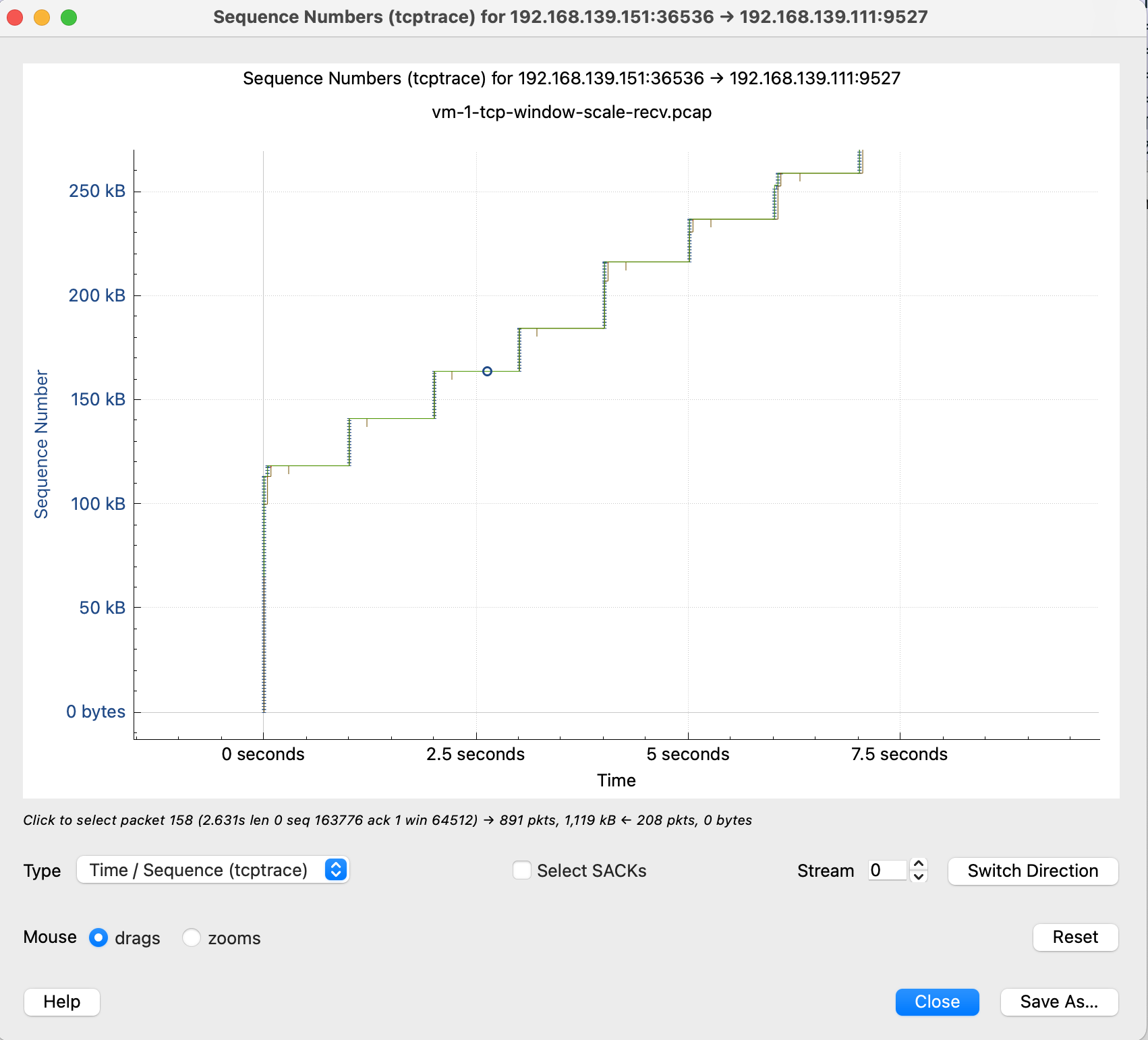
这张图鼠标可点击的点更多,比如我这里点 x 轴的点,会直接跳转到对应的包 Frame 112 是 keep-alive 下一个包 113 是 TCP ZeroWindow,从 116 到 132 都是 vm-2 给 vm-1 发送数据 代表y 轴上升的线证明有数据发送,113-116 表示 vm-1 没有窗口接收了,参照代码正是读一会停一会,换到正常业务就是服务端处理的比较慢
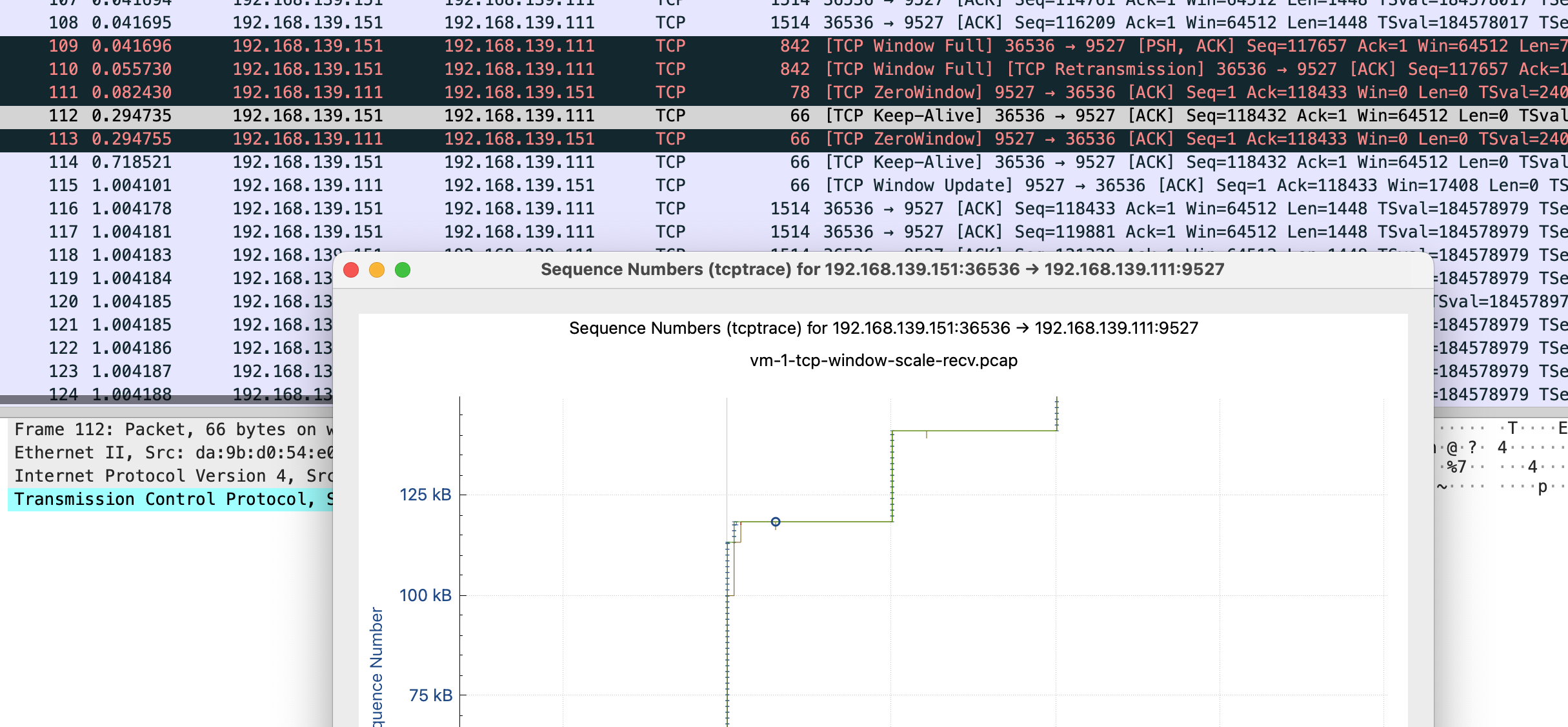
tcp window full - tcp 窗口已满
tcp zerowindow - 接收方无法处理更多数据
tcp window update - 有缓冲区可以处理,请继续发送
110 号包到 116 是第一段 x 轴线平了未发送数据阶段,111 是 vm-1 告诉 vm-2 我无法接收更多数据,直到 115 vm-1 发送 window update,跟 vm-2 说你可以发送数据了。
wireshark-tcp-window-zero-update-full
此部分暂时不做测试,接触的较少。
实验流程来自 知识星球:程序员踩坑案例分享
同样 vm-2 连接 vm-1,然后 vm-2 做为客户端断开连接
sudo tcpdump -s0 -X -nn "tcp port 9527" -w vm-1-tcp_close.pcap --print

很正常的三次握手连接之后四次挥手关闭连接,一切正常
在看 vm-2 上的连接状态,正常进入 TIME_WAIT 等待 2 * MSL 时间是 60s,没有重试就是在等待
$ sudo netstat -anpo|grep Recv-Q;sudo netstat -anpo|grep 9527
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 0 192.168.139.151:58966 192.168.139.111:9527 ESTABLISHED 34043/nc off (0.00/0/0)
$ sudo netstat -anpo|grep Recv-Q;sudo netstat -anpo|grep 9527
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 0 192.168.139.151:58966 192.168.139.111:9527 TIME_WAIT - timewait (57.43/0/0)
$ sudo netstat -anpo|grep Recv-Q;sudo netstat -anpo|grep 9527
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 0 192.168.139.151:58966 192.168.139.111:9527 TIME_WAIT - timewait (46.88/0/0)
$ sudo netstat -anpo|grep Recv-Q;sudo netstat -anpo|grep 9527
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 0 192.168.139.151:58966 192.168.139.111:9527 TIME_WAIT - timewait (39.88/0/0)
$ sudo sysctl -w net.ipv4.tcp_max_tw_buckets=1000000
net.ipv4.tcp_max_tw_buckets = 1000000
$ sudo sysctl -w net.ipv4.tcp_tw_reuse=0
net.ipv4.tcp_tw_reuse = 0
$ cat loopconnect.py
import socket
def connect_and_immediately_disconnect(host, port, count):
try:
for i in range(count):
cli = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
cli.connect((host, port))
cli.close()
except Exception as e:
print(f"Failed to connect: {e}")
if __name__ == '__main__':
connect_and_immediately_disconnect('192.168.139.111', 9527, 70000)
然后测试发现机器的 TIME_WAIT 到 5000 左右就上不去了,无法复现无可用地址的错误,尝试将参数缩小5倍,在将本地可用端口范围变小,能看到达到 233 个 TIME_WAIT 提示无可用地址
$ sudo sysctl -w net.ipv4.ip_local_port_range="32768 33000"
net.ipv4.ip_local_port_range = 32768 33000
$ python3 loopconnect.py
Failed to connect: [Errno 99] Cannot assign requested address
$ sudo netstat -anpo|grep 9527|grep timewait|wc -l
233
然后开启 net.ipv4.tcp_tw_reuse 参数,将本地可用端口扩大些
$ sudo sysctl net.ipv4.tcp_tw_reuse net.ipv4.ip_local_port_range net.ipv4.tcp_max_tw_buckets
net.ipv4.tcp_tw_reuse = 1
net.ipv4.ip_local_port_range = 32768 38414
net.ipv4.tcp_max_tw_buckets = 200000
查看 TIME_WAIT 数量,稳定在 2000 多,脚本正常跑完退出
$ sudo netstat -anpo|grep 9527|grep timewait|wc -l
2287
2301
2303
2303
2269
2291
2292
2322
$ sudo sysctl -w net.ipv4.tcp_tw_reuse=0
net.ipv4.tcp_tw_reuse = 0
$ sudo sysctl -w net.ipv4.tcp_max_tw_buckets=1000
net.ipv4.tcp_max_tw_buckets = 1000
$ sudo netstat -anpo|grep 9527|grep timewait|wc -l
1000
1000
1000
基本相同,TIME_WAIT 大部分是 1000,监测一会会出现 900 多的状况,我猜测是超过了 2 * MSL 后本地可用地址被释放出来,继续被使用 因为关闭了 tw_reuse 不会被重用,只会等待有可用的地址在继续使用
连接脚本中是 14000 个连接,也就是有 11353 个连接没等待 TIME_WAIT 的 60s 直接被系统处理了
$ sudo netstat -s|grep TCPTimeWaitOverflow
TCPTimeWaitOverflow: 11353
vm-2 连接 vm-1,连接后在 vm-1 drop vm-2 发送过来的 FIN,vm-2 发送一个 FIN 后就会进入 FIN1 状态
$ sudo iptables -A INPUT -p tcp --dport 9527 --tcp-flags FIN FIN -j DROP
$ sudo tcpdump -s0 -X -nn "tcp port 9527" -w vm-1-tcp_close-iptables-fin1.pcap --print
vm-1-tcp_close-iptables-fin1.pcap

vm-2 向 vm-1 发送 FIN,vm-1 直接 drop,vm-2 因为收不到 vm-1 发送的 FIN+ACK 就会重传
能看到 vm-2 的网络状态
$ sudo netstat -anpo|grep -E "Recv|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 1 192.168.139.151:37356 192.168.139.111:9527 FIN_WAIT1 - on (2.52/4/0)
$ sudo netstat -anpo|grep -E "Recv|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 1 192.168.139.151:37356 192.168.139.111:9527 FIN_WAIT1 - on (34.57/8/0)
这 9 次的重传受 net.ipv4.tcp_orphan_retries 影响,默认是 8
tcp_orphan_retries - INTEGER
This value influences the timeout of a locally closed TCP connection, when RTO retransmissions remain unacknowledged. See tcp_retries2 for more details.
The default value is 8.
If your machine is a loaded WEB server, you should think about lowering this value, such sockets may consume significant resources. Cf. tcp_max_orphans.
还是 vm-2 连接 vm-1 后,在 vm-2 使用 iptables 拦截 FIN,断开 vm-2的连接,FIN1 是 vm-2 发送 FIN 后直接就会进入 FIN1 状态,然后 vm-1 发送 ACK 过来 vm-2 就会进入 FIN2 状态,因为我们拦截了 FIN 所以就能观测到 vm-2 的 FIN2 和 vm-1 的 LAST_ACK
$ sudo iptables -A INPUT -p tcp --sport 9527 --tcp-flags FIN FIN -j DROP
$ sudo tcpdump -s0 -X -nn "tcp port 9527" -w vm-1-tcp_close-iptables-fin2.pcap --print
vm-1-tcp_close-iptables-fin2.pcap

能看到 vm-2 这个连接进入了 FIN2 状态,最后的值显示 timewait (多少s/0/0),这个 s 是 60,通过 tcp_fin_timeout 控制,这并不是重传 就是 FIN2 的超时时间,过了 60s 连接就会消失
$ sudo sysctl -a|grep tcp_fin_timeout
net.ipv4.tcp_fin_timeout = 60
$ sudo netstat -anpo|grep -E "Recv|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 0 192.168.139.151:36456 192.168.139.111:9527 FIN_WAIT2 - timewait (57.45/0/0)
$ sudo netstat -anpo|grep -E "Recv|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 0 192.168.139.151:36456 192.168.139.111:9527 FIN_WAIT2 - timewait (54.12/0/0)
vm-1 的 LAST_ACK,能看到也是在重传 9 次
$ sudo netstat -anpo|grep -E "Recv|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 0 192.168.139.111:9527 0.0.0.0:* LISTEN 1091/nc off (0.00/0/0)
tcp 0 0 192.168.139.111:9527 192.168.139.151:36456 ESTABLISHED 1091/nc off (0.00/0/0)
$ sudo netstat -anpo|grep -E "Recv|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 0 192.168.139.111:9527 0.0.0.0:* LISTEN 1091/nc off (0.00/0/0)
tcp 0 1 192.168.139.111:9527 192.168.139.151:36456 LAST_ACK - on (23.09/7/0)
使用 python 连接
import socket
c = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
c.connect(('192.168.139.111', 9527))
c.shutdown(socket.SHUT_WR)
$ sudo tcpdump -s0 -X -nn "tcp port 9527" -w vm-1-tcp_close-iptables-closewait-py.pcap --print
vm-1-tcp_close-iptables-closewait-py.pcap

能看到 vm-2 发送 FIN 后进入 FIN1 状态,vm-2 回复 ACK 就结束了,vm-2 收到 ACK 会进入到 FIN2,而 vm-1 只发送 ACK 自己进入 CLOSE_WAIT
同样 FIN2 等待 60s 后不进入 TIME_WAIT 直接结束状态 此状态和文中是对不上的,发送请求后 vm-2 FIN2 会进入 60s 的等待时间,而文中确不会,目前能看到 vm-1 的 CLOSE_WAIT 是一直存在的
vm-2
$ sudo netstat -anpo|grep -E "Recv|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 0 192.168.139.151:34774 192.168.139.111:9527 FIN_WAIT2 - timewait (55.39/0/0)
$ sudo netstat -anpo|grep -E "Recv|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 0 192.168.139.151:34774 192.168.139.111:9527 FIN_WAIT2 - timewait (31.64/0/0)
-----------------------------------------------------------------
vm-1
$ sudo netstat -anpo|grep 9527
tcp 1 0 192.168.139.111:9527 0.0.0.0:* LISTEN 1268/python3 off (0.00/0/0)
tcp 1 0 192.168.139.111:9527 192.168.139.151:34774 CLOSE_WAIT - off (0.00/0/0)
修改 net.ipv4.tcp_fin_timeout 测试
$ sudo sysctl -w net.ipv4.tcp_fin_timeout=30
$ sudo tcpdump -s0 -X -nn "tcp port 9527" -w vm-1-tcp_close-iptables-closewait-py-30s-timeout.pcap --print
vm-1-tcp_close-iptables-closewait-py-30s-timeout.pcap

vm-1
$ sudo netstat -anpo | grep -E "Recv-Q|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 2 0 192.168.139.111:9527 0.0.0.0:* LISTEN 1268/python3 off (0.00/0/0)
tcp 1 0 192.168.139.111:9527 192.168.139.151:37626 CLOSE_WAIT - off (0.00/0/0)
tcp 1 0 192.168.139.111:9527 192.168.139.151:34774 CLOSE_WAIT - off (0.00/0/0)
-----------------------------------------------------------------
vm-2
$ sudo netstat -anpo | grep -E "Recv-Q|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 0 192.168.139.151:37626 192.168.139.111:9527 FIN_WAIT2 - timewait (26.30/0/0)
$ sudo netstat -anpo | grep -E "Recv-Q|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 0 192.168.139.151:37626 192.168.139.111:9527 FIN_WAIT2 - timewait (0.49/0/0)
看样子是没法豁免的,时间只会随着 net.ipv4.tcp_fin_timeout 变动,可能和内核也有关系贴一下我的系统内核
Linux vm-2 6.17.4-orbstack-00308-g195e9689a04f #1 SMP PREEMPT Fri Oct 24 07:22:34 UTC 2025 aarch64 aarch64 aarch64 GNU/Linux
默认 keepalive 相关参数
$ sudo sysctl net.ipv4.tcp_keepalive_time net.ipv4.tcp_keepalive_probes net.ipv4.tcp_keepalive_intvl
net.ipv4.tcp_keepalive_time = 7200
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_keepalive_intvl = 75
import socket
import time
def connect_and_hold(host, port, count):
cli_list = []
try:
for i in range(count):
cli = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
cli.setsockopt(socket.SOL_SOCKET, socket.SO_KEEPALIVE, 1)
cli.connect((host, port))
cli_list.append(cli)
except Exception as e:
print(f"Failed to connect: {e}")
while True:
time.sleep(1)
if __name__ == '__main__':
connect_and_hold('192.168.139.111', 9527, 1)
$ sudo tcpdump -s0 -X -nn "tcp port 9527" -w vm-1-tcp_close-vm-2-keepalive.pcap --print
vm-1-tcp_close-vm-2-keepalive.pcap

连接后没数据传输,vm-2 每隔 75s 给 vm-1 发送 TCP Keep-Alive,走的 net.ipv4.tcp_keepalive_intvl
vm-2
$ sudo netstat -anpo|grep -E "Recv-Q|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 0 192.168.139.151:37118 192.168.139.111:9527 ESTABLISHED 25305/python3 keepalive (71.33/0/0)
$ sudo netstat -anpo|grep -E "Recv-Q|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 0 192.168.139.151:37118 192.168.139.111:9527 ESTABLISHED 25305/python3 keepalive (70.62/0/0)
叫 grok 改了 python 脚本
import socket
import time # 添加 time 模块以便暂停脚本查看连接状态
c = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
c.setsockopt(socket.SOL_SOCKET, socket.SO_KEEPALIVE, 1)
# 设置 keepalive 参数:TCP_KEEPIDLE 为空闲时间(相当于 net.ipv4.tcp_keepalive_time),单位秒
c.connect(('192.168.139.111', 9527))
# 暂停脚本以便用 netstat -anpo 或 ss -anto 查看连接状态(会显示 keepalive timer 如 timer:keepalive (10.000 sec))
print("连接已建立,按 Enter 退出...")
input() # 或用 time.sleep(60) 自动等待 60 秒
c.close()
$ sudo sysctl -a|grep keep
net.ipv4.tcp_keepalive_intvl = 20
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_keepalive_time = 10
$ sudo tcpdump -s0 -X -nn "tcp port 9527" -w vm-1-tcp_close-vm-2-keepalive-10s.pcap --print
vm-1-tcp_close-vm-2-keepalive-10s.pcap

正常三次握手,然后 vm-2 发了 Keep-Alive vm-1 回复,3和4的包之间隔了 10s 也就是 net.ipv4.tcp_keepalive_time,然后 vm-1 和 vm-2 之间没发送数据,相隔 20s 第6个包 vm-2 发了 Keep-Alive 也就是 net.ipv4.tcp_keepalive_intvl,最后 vm-2 enter 直接断开 发了 FIN+ACK vm-1 回了 ACK 但是没回 FIN vm-1 状态就是 CLOSE_WAIT,vm-2 则是 FIN2 然后根据 fin_time 30s 过去就消失
vm-1
$ sudo netstat -anpo | grep -E "Recv-Q|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 1 0 192.168.139.111:9527 0.0.0.0:* LISTEN 1692/python3 off (0.00/0/0)
tcp 0 0 192.168.139.111:9527 192.168.139.151:33360 ESTABLISHED - off (0.00/0/0)
$ sudo netstat -anpo | grep -E "Recv-Q|9527"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 1 0 192.168.139.111:9527 0.0.0.0:* LISTEN 1692/python3 off (0.00/0/0)
tcp 1 0 192.168.139.111:9527 192.168.139.151:33360 CLOSE_WAIT - off (0.00/0/0)
-----------------------------------------------------------------
vm-2
$ sudo netstat -anpo|grep 9527
tcp 0 0 192.168.139.151:33360 192.168.139.111:9527 ESTABLISHED 27528/python3 keepalive (7.38/0/0)
$ sudo netstat -anpo|grep 9527
tcp 0 0 192.168.139.151:33360 192.168.139.111:9527 ESTABLISHED 27528/python3 keepalive (17.59/0/0)
$ sudo netstat -anpo|grep 9527
tcp 0 0 192.168.139.151:33360 192.168.139.111:9527 FIN_WAIT2 - timewait (26.96/0/0)
$ sudo netstat -anpo|grep 9527
tcp 0 0 192.168.139.151:33360 192.168.139.111:9527 FIN_WAIT2 - timewait (23.06/0/0)
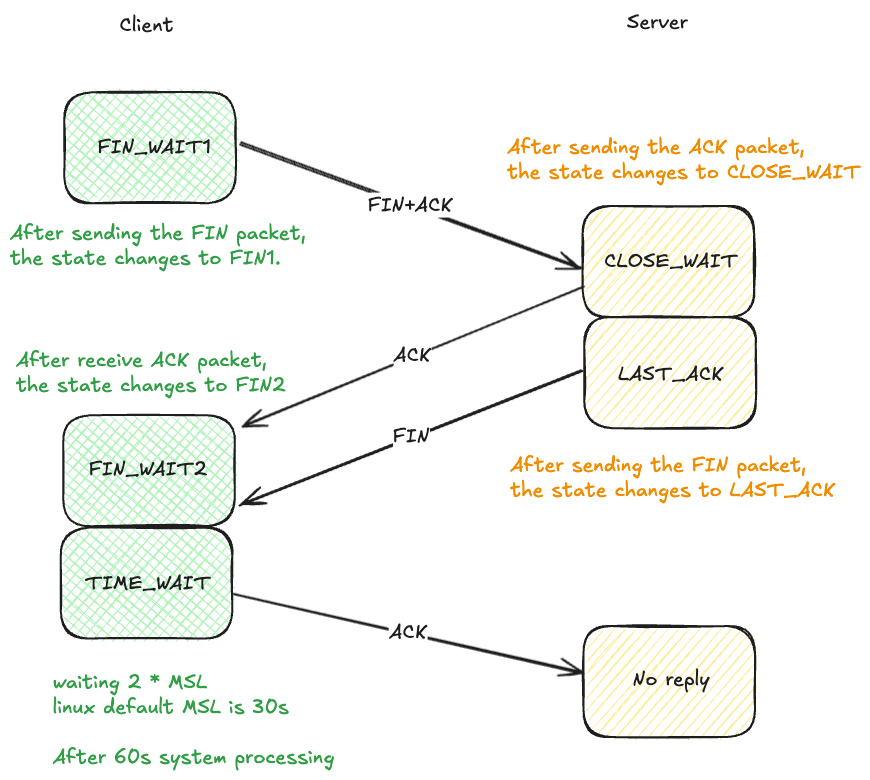
没找到合适的,自己画了个
sudo apt update
sudo apt install -y tcpdump net-tools iptables wget nmap telnet man lsof ipvsadm ipset btop git ca-certificates tmux jq curl gpg file
#cloud-config
package_update: true
package_upgrade: true
packages:
- bridge-utils
- make
- cmake
- pkg-config
- build-essential
- wget
- net-tools
- inetutils-ping
- dnsutils
- vim
- unzip
- zip
- sysstat
- git
- iproute2
- ca-certificates
- telnet
- curl
- htop
- tcpdump
- gnupg
- lsb-release
- btrfs-progs
- libssl-dev
- m4
- gcc
- g++
- clang
- fuse
- tree
- iftop
- jq
- gpg
- man
- tmux
- traceroute
- ethtool
- lz4
- btop
- gh
- qemu-guest-agent
- supervisor
bootcmd:
- mkdir -p /opt/docker/cadvisor
- mkdir -p /opt/docker/node_exporter
write_files:
- path: /opt/docker/node_exporter/compose.yaml
owner: root:root
permissions: 0o755
defer: true
content: |
services:
node_exporter:
image: quay.io/prometheus/node-exporter:latest
container_name: node_exporter
command:
- '--web.listen-address=:10000'
- '--path.rootfs=/host'
network_mode: host
pid: host
restart: unless-stopped
volumes:
- '/:/host:ro,rslave'
- path: /opt/docker/cadvisor/compose.yaml
owner: root:root
permissions: 0o755
content: |
services:
cadvisor:
image: gcr.io/cadvisor/cadvisor:latest
container_name: cadvisor
privileged: true
devices:
- /dev/kmsg:/dev/kmsg
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
ports:
- "10001:8080"
restart: unless-stopped
runcmd:
- install -m 0755 -d /etc/apt/keyrings
- curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
- chmod a+r /etc/apt/keyrings/docker.asc
- echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu $(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}") stable" | tee /etc/apt/sources.list.d/docker.list > /dev/null
- apt update
- apt install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
- systemctl enable docker
- systemctl enable qemu-guest-agent
- systemctl start qemu-guest-agent
- systemctl start docker
- docker compose -f /opt/docker/node_exporter/compose.yaml up -d
- docker compose -f /opt/docker/cadvisor/compose.yaml up -d
users:
- default
- name: orange723
sudo: "ALL=(ALL) NOPASSWD:ALL"
groups: sudo, sys, root, adm, docker
shell: /bin/bash
homedir: /home/orange723
lock_passwd: true
ssh_authorized_keys:
- ssh-ed25519 AAAAC
no_ssh_fingerprints: true
ssh:
emit_keys_to_console: false
# It is recommended to clear the `GOROOT`, `GOBIN`, and other environment variables before installation.
$ curl -sSL https://raw.githubusercontent.com/voidint/g/master/install.sh | bash
$ cat << 'EOF' >> ~/.bashrc
# Check if the alias 'g' exists before trying to unalias it
if [[ -n $(alias g 2>/dev/null) ]]; then
unalias g
fi
EOF
$ source "$HOME/.g/env"
$ g ls-remote stable
$ g install stable
$ curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.3/install.sh | bash
$ nvm install --lts
$ nvm use --lts
使用 nvm 要注意多版本,比如 gemini 装到 A 版本 node,但目前是在用 B 版本 node,调用会提示找不到